Abstract
Mixture-of-Experts (MoE) models provide a natural path for scaling open foundation models: they increase total parameter capacity while activating only a small subset of experts per token. However, adapting large MoE models remains difficult outside centralized high-bandwidth clusters, since standard distributed training methods require either dense synchronization, full-model residency, or expensive cross-device communication.
We introduce Connito, a decentralized framework for sparse MoE adaptation. Connito trains only a selected subset of target experts for a given domain, reducing the model state and communication payload required from each worker. This preserves part of the pretrained model's background capacity while keeping worker-side computation small.
Connito combines this sparse training architecture with a Proof-of-Loss incentive mechanism: workers submit updated target experts, validators evaluate their utility on held-out data, and useful updates are integrated back into the global MoE. Together, these components turn model improvement into a distributed process of expert-level contribution, evaluation, and integration. Connito offers a path toward continuously improving open MoE models whose capabilities compound through reusable expert updates rather than repeated centralized retraining.
1. Introduction
Frontier foundation models are increasingly expensive to train and adapt, often requiring centralized GPU clusters, high-bandwidth interconnects, and specialized engineering teams. This creates a barrier for open-model development: although open weights and open data are essential for broad scientific participation, the ability to improve frontier-scale models remains concentrated among a small number of organizations with sufficient compute and infrastructure. The ATOM Project argues that open model weights, data, and training processes are central artifacts for AI research, because they allow a wider community to inspect, reproduce, and improve foundation models rather than depending exclusively on closed systems (Wu, Rao, and W. Chen 2024).
Mixture-of-Experts (MoE) architectures offer a natural path toward more scalable open-model improvement. Unlike dense models, MoE models decouple total parameter capacity from active computation by routing each token to only a small subset of experts (Shazeer et al. 2017; Fedus, Zoph, and Shazeer 2022). This sparse structure makes MoE models inherently modular: experts can specialize in different domains, be selectively updated, and be composed back into a larger model (for a detailed survey of these modular characteristics and their historical milestones, see Appendix A). However, standard distributed training methods do not fully exploit this modularity. Dense data parallelism typically requires synchronizing a large fraction of the model state, while pipeline parallelism depends on transmitting activations and gradients between stages, which can become costly in open-internet settings with limited or variable bandwidth.
Connito is motivated by the observation that open-model scaling does not need to rely only on repeated centralized retraining. Instead, an MoE model can be improved through sparse, expert-level updates. For a target domain, only a small subset of experts may need to be trained, while the rest of the model can remain frozen. Prior work such as ESFT shows that task-relevant experts can be selectively fine-tuned while preserving strong downstream performance (Wang et al. 2024). At the same time, training with only the selected experts can remove useful background computation that the original pretrained MoE would have provided.
Coordinating an open network of untrusted contributors requires a robust mechanism to evaluate their work. Building on this sparse training architecture, Connito introduces an Intelligent Market for decentralized MoE adaptation. Workers train selected target experts on local data and submit updated expert weights. Validators evaluate which submissions most improve the global model through a Proof-of-Loss mechanism, and useful updates are integrated back into the full foundation MoE. In this framework, the market is not merely selecting which experts are relevant to a dataset; it is selecting which worker contribution within a selected expert set provides the most valuable update to the global model. This turns open-model improvement into a distributed process of expert-level contribution, evaluation, and integration.
This paper makes the following contributions:
- We propose a sparse MoE adaptation framework that trains only selected target experts, reducing the model state and communication payload required from each worker.
- We define a decentralized Proof-of-Loss mechanism that scores worker submissions by their empirical contribution to held-out validation loss.
- We establish a framework for how expert-level modularity enables an open model to improve continuously through reusable, composable expert updates.
3. Distributed Training Framework
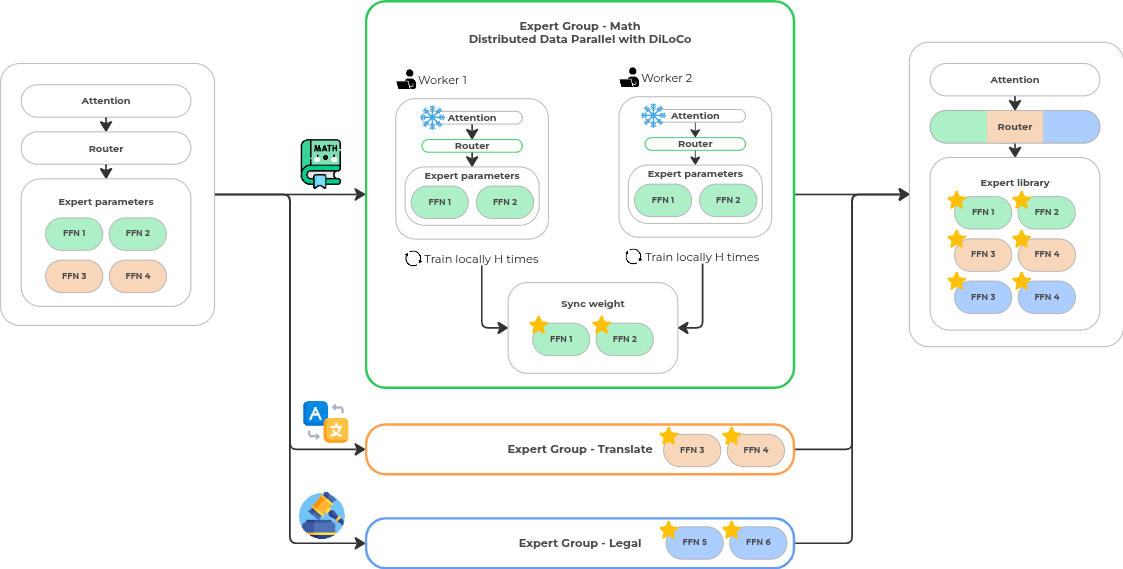
Connito trains a sparse MoE model by updating only selected target experts while keeping the shared parameters, router, and training-time context fixed. This section describes the machine-learning workflow assuming honest workers; the incentive and adversarial setting is handled separately in Section 4. The goal is to reduce the model state and communication payload required from each worker while preserving enough background computation for stable fine-tuning.
Let the full pretrained MoE model be
where denotes shared non-expert parameters such as attention layers, embeddings, and layer normalization; denotes the pretrained router; and denotes the full collection of pretrained expert weights:
Here, is the number of MoE layers and is the number of routed experts per layer.
3.1 Phase 1: Target Expert Selection
The first phase selects the experts to be updated for a target domain. Following ESFT and DES-MoE, we use pretrained routing behavior to identify domain-relevant experts (Wang et al. 2024; J. Li et al. 2025a). Given target data , the protocol computes a selection map
where each denotes the target experts selected at layer . The selection rule may use routing probability mass, activation frequency, or a differential score comparing against a general-domain dataset .
The selected set defines which experts receive gradients. It does not define the entire forward-pass model: non-selected experts may still contain useful background computation, even if they are not worth updating for the target domain.
3.2 Phase 2: Sparse Local Optimization
This phase performs local training on the selected target experts. It follows the local-training pattern of DiLoCo and Branch-Train-Merge, where workers perform multiple local steps before global synchronization (Douillard et al. 2024; M. Li et al. 2022).
Let the initial trainable state be defined as . At global step , a worker receives the current trainable target expert state
The worker then performs local optimization steps on its local data partition using as the forward-pass model:
After local training, worker submits only the updated target expert weights . No updates are submitted for the shared parameters or router.
3.3 Phase 3: Frozen Routing Anchor
The routing function is inherited from the pretrained model and remains fixed during local training. This follows ESFT's frozen-router setup and is also aligned with FlexOLMo's anchor-based expert training, where independently trained experts remain compatible because they are trained against a shared reference (Wang et al. 2024; Shi et al. 2025).
For an input token representation at layer , the pretrained router computes
During compressed local training, the available expert set consists of the selected target experts . Freezing makes worker updates comparable because all workers optimize against the same routing distribution and shared anchor.
3.4 Phase 4: Global Integration
The final phase aggregates worker submissions and integrates the resulting target expert update back into the full pretrained MoE. Assuming honest workers, the aggregator receives and computes a weighted update to the target expert state. In the simplest case, the updated target experts are averaged:
where is an aggregation weight and . Uniform averaging sets ; validation-weighted aggregation can assign larger weights to submissions that improve held-out loss.
After training, the final target expert weights are inserted back into the original full foundation model:
Here, denotes replacing the pretrained target experts in with their fine-tuned values.
4. Decentralized Incentive Mechanism
The distributed training framework in Section 3 assumes honest workers. In an open subnet, however, workers may have heterogeneous hardware, different data quality, and strategic incentives. Connito therefore separates the machine-learning update rule from the incentive layer. The role of the incentive mechanism is to evaluate submitted target-expert updates, reward useful work, and prevent low-effort or adversarial submissions from shaping the global model.
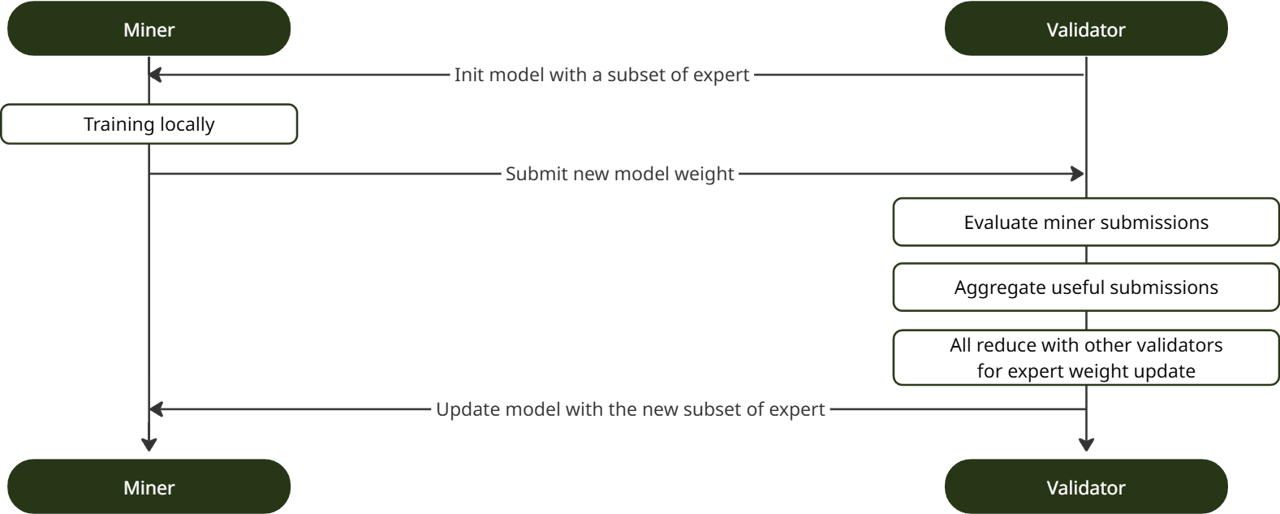
4.1 Miners and Validators
Connito separates participants into two roles. Miners perform local optimization on the selected target expert parameters and submit updated target expert weights. Validators evaluate these submissions, assign rewards, and maintain the global model state.
Training proceeds in synchronous communication cycles. Each cycle contains a training window, a commit window, and a submit window. During training, miners optimize the selected target experts on local data. During commit, miners publish a cryptographic commitment to their checkpoint. During submit, miners reveal the corresponding checkpoint for evaluation. Submissions outside the expected window are rejected, keeping all participants aligned to the same global training state.
4.2 Proof-of-Loss Evaluation
Connito scores miner submissions using Proof-of-Loss: validators measure whether a submitted target-expert update improves the global model on a held-out validation subset. Let denote the current global target expert state and let denote miner 's submitted target expert weights after local training. The validator evaluates the validation loss after applying the submitted update to a copy of the model:
The miner's utility is measured relative to the current global model:
Only positive loss reduction is rewarded. Submissions that do not improve validation loss receive zero utility.
The validation subset is deterministically sampled from the target distribution for each cycle. This ensures that validators evaluate the same objective and reduces the incentive to optimize for unrelated public benchmarks. In practice, this validation procedure is the core mechanism that turns local expert training into a competitive update-selection process.
4.3 Reward Assignment and Global Update Selection
Connito assigns rewards by ranking miners within each cycle by validation loss. Because each cycle uses a randomly sampled validation subset, raw loss values are not directly comparable across cycles; rankings provide a more stable relative signal. Miners in the top- receive emissions, with higher-ranked submissions receiving more points.
Let be the rank of miner in cycle , where rank 1 denotes the lowest validation loss. Rewards from a validator are assigned by a decreasing rank function:
where is positive for top- miners and zero otherwise.
Model integration is independent of reward assignment. The protocol may reward the top- miners by rank, while aggregating a selected subset of top-ranked submissions into the global model. Following DiLoCo-style outer optimization, integration is performed on pseudo-gradients computed from weight displacements, rather than on the submitted weights directly.
Let denote the set of top-ranked submissions in cycle . For each selected miner , the aggregator computes a pseudo-gradient from the submitted target expert weights:
The selected pseudo-gradients are then merged by weighted averaging:
The outer optimizer is applied to the merged pseudo-gradient, not directly to the submitted weights:
This design allows the subnet to reward multiple useful contributors while integrating only the update that provides the strongest measured improvement in a given cycle. The broader choice between top-ranked integration and weighted aggregation is an implementation parameter; both use the same Proof-of-Loss scoring signal.
4.4 Commit-Reveal and Evaluation Randomness
Permissionless training requires protection against free-riding, copying, and post-hoc optimization against the validation set. Connito uses a commit-reveal mechanism to bind miners to a checkpoint before the evaluation data is fully determined. During the commit window, miner publishes
During the submit window, the miner reveals the checkpoint, and validators verify that its hash matches .
The evaluation seed is generated from validator-provided randomness:
where is validator 's random seed for the cycle. The seed determines validator assignment and the held-out validation subset. Because no single miner controls all validator seeds, miners cannot reliably know the exact evaluation partition before committing to their checkpoint.
4.5 Security Goals
The incentive mechanism is designed around three practical security goals:
- Utility alignment: rewards should track measurable improvement on held-out validation data from the target domain.
- Copy resistance: commit-reveal should prevent miners from copying another miner's checkpoint after observing submissions.
- Evaluation unpredictability: validation partitions should be deterministic for validators but difficult for miners to predict before committing.
Together, these mechanisms allow Connito to coordinate open participation without assuming that every worker is honest or equally capable. Miners compete to produce useful expert updates, validators measure the empirical value of those updates, and the global model evolves through submissions that improve held-out loss.
5. System Analysis
Connito is structurally designed to reduce the cost of distributed MoE adaptation by exploiting expert-level sparsity. In dense distributed training, each worker typically maintains and synchronizes a large fraction of the full model state. Connito alters the memory and communication bounds of this process by separating three distinct sources of efficiency: sparse payload communication, reduced optimizer-state memory, and update-filtering via Proof-of-Loss.
5.1 Communication Complexity and Sparse Upload
In Connito, the trainable and transmitted payload is strictly restricted to the selected target expert subset . As a result, the communication cost per round scales with the size of rather than the full pretrained model .
Let be the total parameter count of the MoE, and be the parameter count of the selected target experts. The communication payload per worker per round is reduced proportionally by . Furthermore, because workers perform local optimization steps before committing an update, the amortized communication cost per local gradient step becomes . This compression is structural — arising from the MoE decomposition itself — and is fully complementary to quantization, gradient sparsification, and reduced synchronization frequency.
5.2 Worker-Side VRAM
Instead of instantiating all omitted non-target experts, workers use the compressed training model
Because and remain frozen, they do not receive gradients and require no optimizer-state memory (e.g., Adam moments). This reduces the active expert state required during local training while preserving part of the background computation that would otherwise be provided by the full frozen expert pool.
5.3 Proof-of-Loss as an Optimization Filter
Beyond hardware efficiency, Connito's incentive layer treats decentralized training as an update-selection problem. Proof-of-Loss evaluates submitted target expert weights by their effect on held-out validation loss. This mechanism provides a clear, empirical coordination signal for a heterogeneous worker network, allowing the system to reward useful local work and systematically reject updates that do not improve the global model.
6. Future Outlook
Connito targets organizations that need deeper model customization than generic foundation models, prompt engineering, or lightweight PEFT methods can reliably provide. In domains such as legal, finance, healthcare, coding, compliance, and enterprise knowledge work, customers often need models to internalize domain-specific schemas, terminology, workflows, and reasoning patterns. Connito packages this need as a managed adaptation workflow: customers provide domain objectives or data, the network produces validated expert updates, and the resulting capabilities become reusable components rather than isolated one-off fine-tunes.
The long-term goal is to make open-model improvement compounding. As more domains are served, validated expert updates can form a shared expert library: a pool of specialized model components that can be selected, reused, and further improved for future tasks. This creates a flywheel in which each deployment can lower the cost and improve the quality of later deployments. Rather than treating model customization as bespoke consulting or repeated centralized retraining, Connito aims to turn it into durable infrastructure for continuously improving, community-built MoE models.
References
- Chen, Tianyu et al. (2022). Task-Specific Expert Pruning for Sparse Mixture-of-Experts. arXiv: 2206.00277.
- Dai, Damai et al. (2024). DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. arXiv: 2401.06066.
- Douillard, Arthur et al. (2024). DiLoCo: Distributed Low-Communication Training of Language Models. arXiv: 2311.08105.
- Fedus, William, Barret Zoph, and Noam Shazeer (2022). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv: 2101.03961.
- Foundation, Opentensor (2023). BitTensor: A Peer-to-Peer Intelligence Market. Tech. rep. Bittensor Foundation. bittensor.com/whitepaper.
- Hu, Edward et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv: 2106.09685.
- Hu, Gang et al. (2025). FFT-MoE: Efficient Federated Fine-Tuning for Foundation Models via Large-scale Sparse MoE under Heterogeneous Edge. arXiv: 2508.18663.
- Hu, Guimin et al. (2026). What Gets Activated: Uncovering Domain and Driver Experts in MoE Language Models. arXiv: 2601.10159.
- Li, Junzhuo et al. (2025). Dynamic Expert Specialization: Towards Catastrophic Forgetting-Free Multi-Domain MoE Adaptation. arXiv: 2509.16882.
- Li, Margaret et al. (2022). Branch-Train-Merge: Embarrassingly Parallel Training of Expert Language Models. arXiv: 2208.03306.
- Lu, Xudong et al. (2024). "Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models." In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pp. 6159–6172. aclanthology.org/2024.acl-long.334.
- Rajbhandari, Samyam et al. (2022). DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale. arXiv: 2201.05596.
- Shazeer, Noam et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv: 1701.06538.
- Shi, Weijia et al. (2025). FlexOlmo: Open Language Models for Flexible Data Use. arXiv: 2507.07024.
- Sukhbaatar, Sainbayar et al. (2024). Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM. arXiv: 2403.07816.
- Wang, Zihan et al. (2024). Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models. arXiv: 2407.01906.
- Wu, Xiaofeng, Jia Rao, and Wei Chen (2024). ATOM: Asynchronous Training of Massive Models for Deep Learning in a Decentralized Environment. arXiv: 2403.10504.
- Xie, Yanyue et al. (2024). MoE-Pruner: Pruning Mixture-of-Experts Large Language Model using the Hints from Its Router. arXiv: 2410.12013.
- Yang, Cheng et al. (2024). "MoE-I2: Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition." In: Findings of the ACL: EMNLP 2024, pp. 10456–10466. aclanthology.org/2024.findings-emnlp.612.
- Yuan, Yichao, Lin Ma, and Nishil Talati (2025). MoE-Lens: Towards the Hardware Limit of High-Throughput MoE LLM Serving Under Resource Constraints. arXiv: 2504.09345.
- Zhang, Qizhen, Prajjwal Bhargava, et al. (2025). BTS: Harmonizing Specialized Experts into a Generalist LLM. arXiv: 2502.00075.
- Zhang, Qizhen, Nikolas Gritsch, et al. (2024). BAM! Just Like That: Simple and Efficient Parameter Upcycling for Mixture of Experts. arXiv: 2408.08274.
- Zhou, Yanqi et al. (2022). Mixture-of-Experts with Expert Choice Routing. arXiv: 2202.09368.
Appendix A: Model Modularity in Practice
We organize the literature around four milestones that collectively characterize modular large language models. We begin with Milestone 0, which establishes the core properties and empirical advantages of Mixture-of-Experts (MoE) architectures. Milestone 1 then examines selective adaptation, showing how partial expert updates enable efficient fine-tuning without modifying the full model. Building on this, Milestone 2 focuses on composable specialization, demonstrating how experts trained on different domains can be combined to improve cross-domain performance. Milestone 3 addresses the practical interfaces required for expert composition, including routing mechanisms and learned connectors that coordinate expert interaction. Finally, Milestone 4 explores expert lifecycle management, covering pruning, removal, and replacement of experts to support long-term model evolution.
A.1 Milestone 0: Demonstration of MoE Characteristic
A.1.1 Shared Expert (Hub)
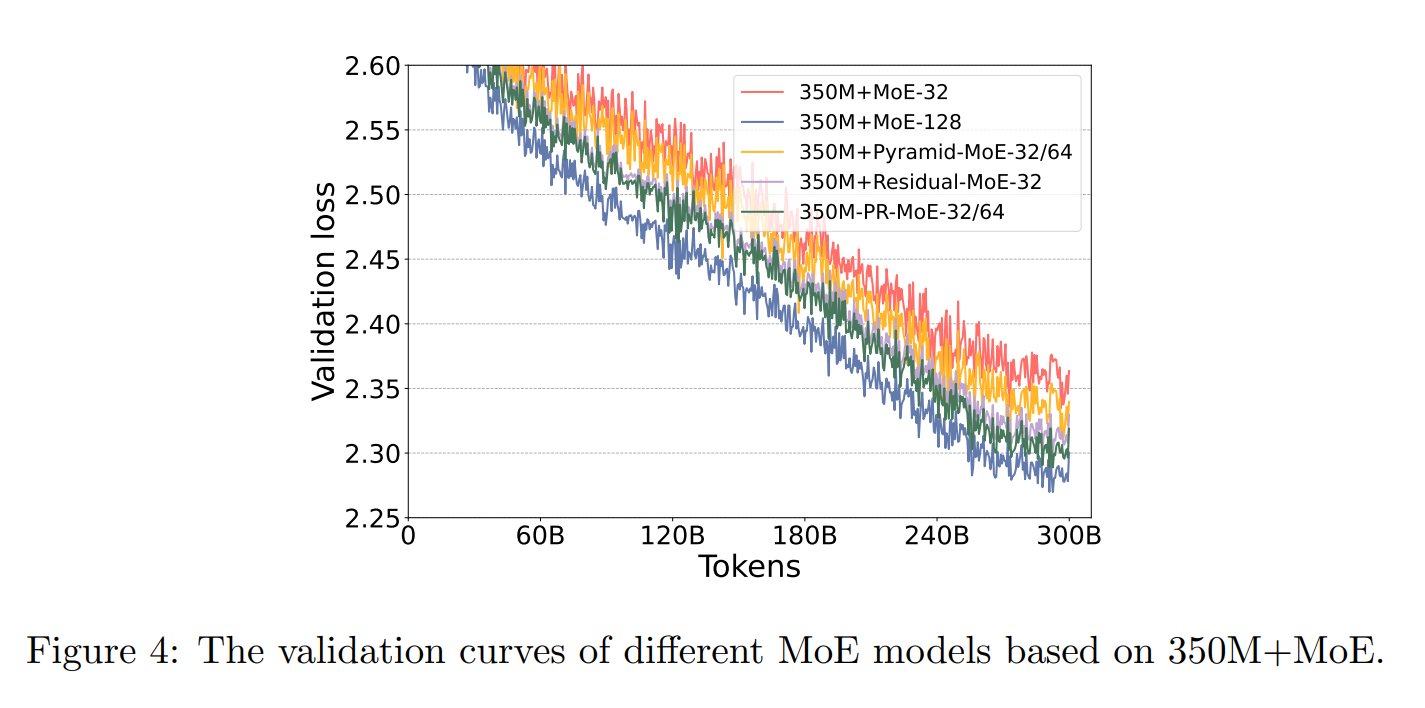
A common design pattern in Mixture-of-Experts (MoE) models is to include a shared expert: a dense MLP (or a small set of experts) that is applied to all tokens, in addition to the sparsely routed experts. This "shared + routed" structure is often used to improve training stability and preserve a strong general-purpose pathway, while still allowing routed experts to specialize. Variants of this idea appear in several MoE systems, including Residual-MoE (Rajbhandari et al. 2022) and DeepSeekMoE (Dai et al. 2024).
Shared experts play a critical role in our modular model by providing a common representational space that aligns and integrates outputs from multiple experts.
Residual-MoE (DeepSpeed). Microsoft proposes Residual-MoE (Rajbhandari et al. 2022), where each MoE layer consists of a fixed dense MLP (the shared expert) together with a sparse set of routed experts. For each token, the model computes the shared expert output and the output of a single routed expert selected by the router, then combines them additively in a residual-style form. Intuitively, the dense pathway provides a stable general representation, while the routed expert acts as an "error-correction" term that captures token-specific specialization:
In their experiments, only a single expert is selected from the available experts to enable direct comparison with top-2 MoE baselines.
Shared Expert Isolation (DeepSeekMoE). DeepSeekMoE introduces Shared Expert Isolation (Dai et al. 2024), which can be interpreted as a hub-style mechanism that separates common knowledge from specialized expertise. Concretely, each MoE layer designates experts as shared experts that are always activated for every token, independent of the router. The remaining experts are treated as routed specialists. This design aims to compress broadly useful "common knowledge" into the shared experts, reducing redundancy among routed experts and encouraging the routed experts to specialize on more distinctive patterns:
Here, the experts with indices correspond to the shared experts (the "hub"), while the remaining experts are selected by top- routing.
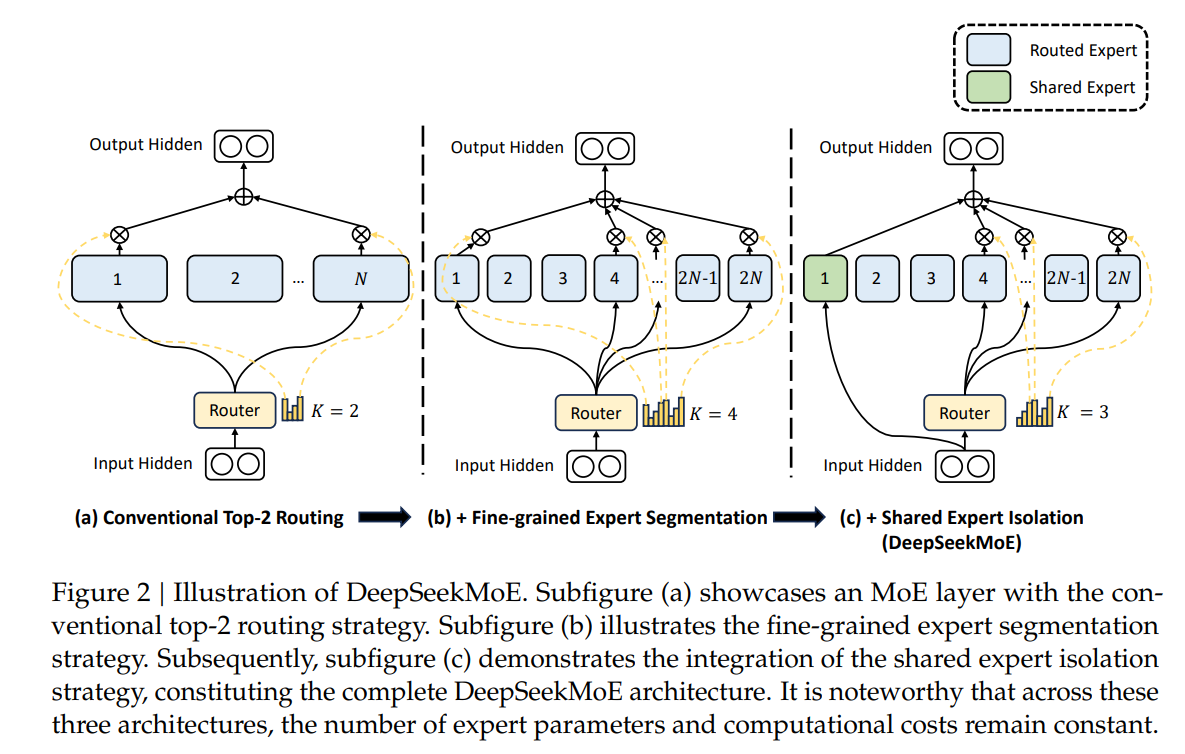
Other occurrences. Similar shared-expert patterns have also been reported in other recent MoE architectures, such as Qwen3 MoE, although the exact implementation details may differ across model families.
A.1.2 The Role of Experts in LLMs
Recent work analyzes router behavior in Mixture-of-Experts (MoE) language models to characterize the functional roles of individual experts. In Guimin Hu et al. (2026), two primary roles are identified: domain experts and driver experts. Domain experts are detected using an entropy-based specialization metric that measures how concentrated an expert's routing distribution is over specific domains. Driver experts are identified via a causal-effect metric that perturbs routing probabilities and measures the resulting change in the model's output distribution.
Empirical results show that only a small fraction of experts exhibit strong domain specialization, while most experts display weak or negligible domain-specific behavior. Increasing router weights for identified domain and driver experts improves accuracy across models. The identification of driver experts would be essential to our project, since it helps us identify and build up the required shared experts from a model.
A.1.3 Low Expert Utilization
Several studies examine how experts are utilized during inference and find that MoE models rely on a small subset of experts. Yuan, Ma, and Talati (2025) analyzed routing distributions across domains and traced expert contributions to the residual stream using early decoding; the analysis shows that a single expert is often sufficient to approximate next-token prediction outputs. Overall, the results indicate that many experts contribute minimally to final predictions, motivating pruning and sparsification strategies that preserve accuracy while improving efficiency. Similar low expert utilization is reported in Wang et al. (2024).
This result is important because it suggests that fine-tuning and inference often do not require the full set of experts, enabling simpler, lower-cost distributed training designs with reduced overhead.
A.1.4 Relationships Between Experts
Recent analyses from Wang et al. (2024) further explore relationships between experts by examining co-activation and routing correlations within MoE layers. The results reveal structured patterns of redundancy and cooperation, where subsets of experts exhibit correlated behavior while others act more independently.
Understanding these relationships reveals expert redundancy and specialization boundaries, which can guide structured pruning, expert merging, and model compression. More broadly, it reinforces that MoE architectures naturally support distributed training by enabling modular updates and coordination across experts.
A.2 Milestone 1: Selective Adaptation via Partial Expert Updates
A defining advantage of modular architectures, such as Mixture-of-Experts (MoE) models, is their ability to adapt by updating only a subset of parameters — typically experts or routing components — rather than fine-tuning the entire model. Prior work shows that selectively adapting experts can improve domain specialization, reduce interference between tasks, and significantly lower training cost.
A.2.1 Domain-Composable Adaptation via Routing and Gradient Control
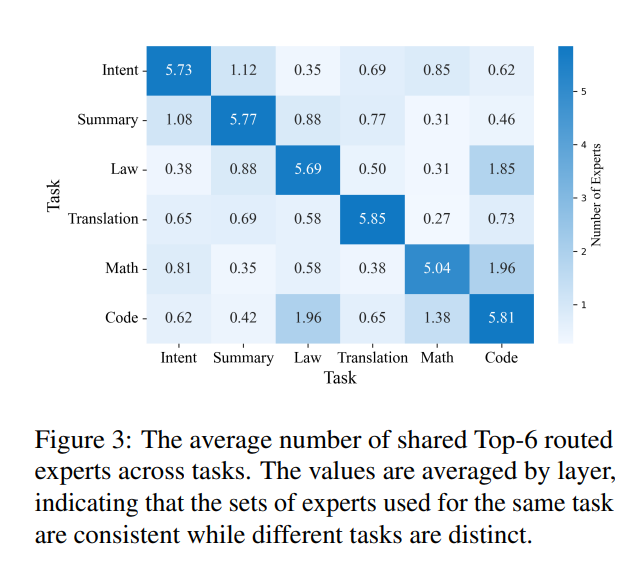
Dynamic Expert Specialization (DES-MoE). DES-MoE studies multi-domain adaptation under catastrophic forgetting and proposes mechanisms that encourage domain specialization while minimizing interference across domains. It introduces an Adaptive Lightweight Router (ALR) trained with a distillation objective, which keeps the fine-tuned router close to the pretrained routing behavior early in training and gradually allows domain-specific routing as adaptation proceeds. In addition, DES-MoE builds an expert–domain correlation map by tracking expert activation frequencies during a warm-up phase, then masks gradients so that domain updates primarily modify experts most associated with that domain. Together, these techniques enable stable domain adaptation and encourage experts to remain reusable across domains (J. Li et al. 2025).
A.2.2 Dynamic Routing
Expert Choice Routing. Expert Choice Routing redefines the routing paradigm by allowing each expert to select its top- tokens, instead of requiring each token to choose a fixed number of experts (Zhou et al. 2022). This design eliminates load imbalance and provides experts with predictable work allocation, leading to more efficient utilization of compute resources. As a result, Expert Choice supports a variable number of experts per token and scales effectively as the total number of experts increases. Empirically, it achieves more than faster training convergence than Switch (top-1) and GShard (top-2) routing under the same compute budget, while maintaining strong model performance.
A.3 Milestone 2: Composable Specialization Across Experts
A second defining property of modular architectures is compositionality: experts trained independently on different domains can be combined to improve performance on the union of those domains, without retraining a single monolithic model. Recent MoE research explores this idea from multiple angles, including domain-aware expert adaptation, expert-level parameter-efficient fine-tuning, and explicit expert merging.
A.3.1 Task-Specific Expert Selection and Reuse
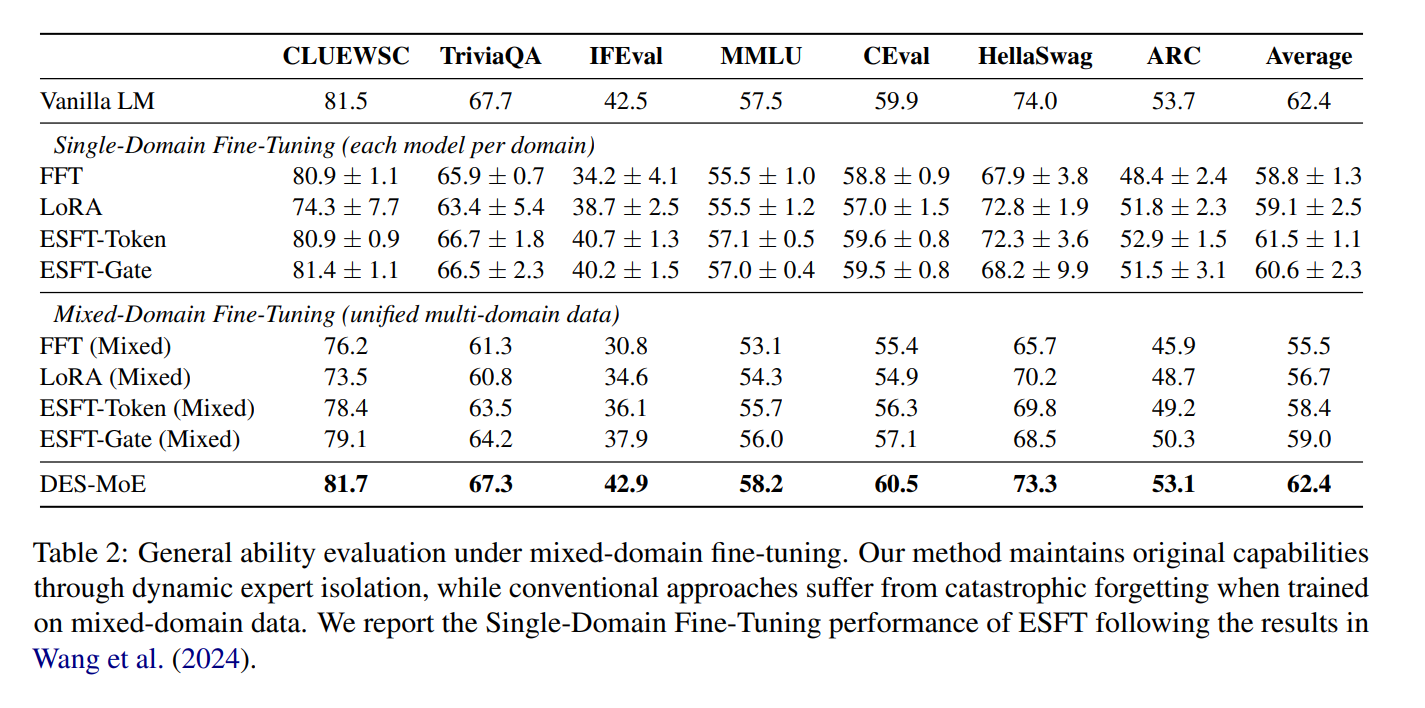
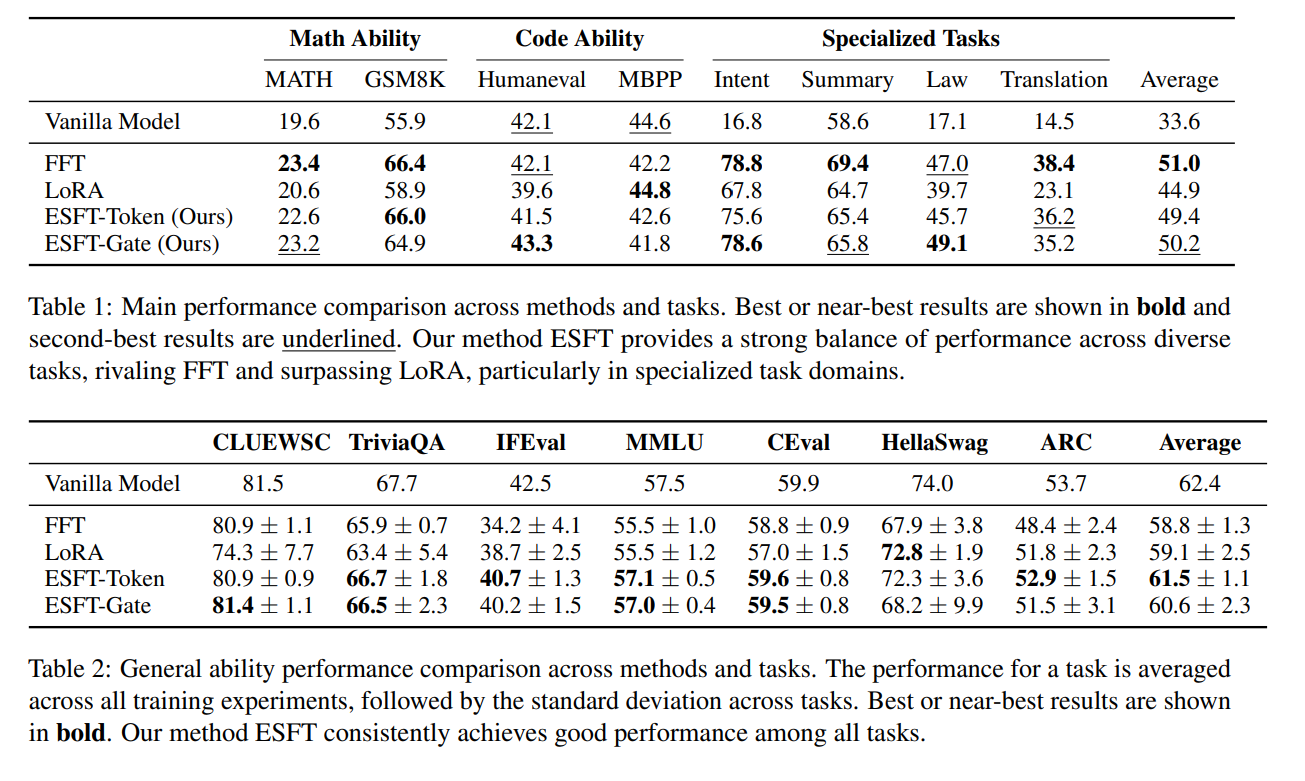
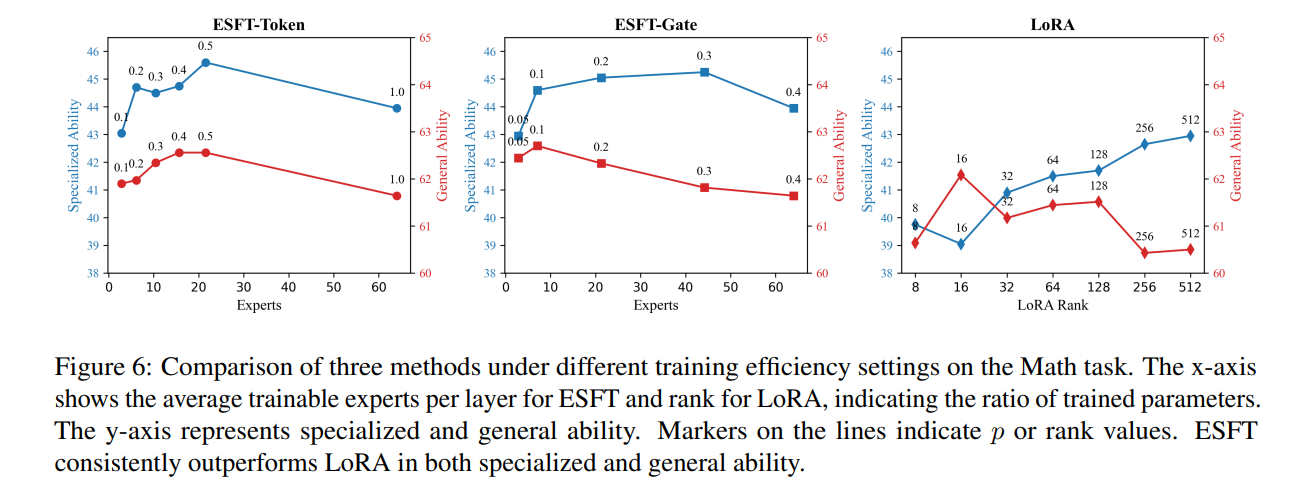
Expert-Specialized Fine-Tuning (ESFT). DeepSeek introduces ESFT, motivated by the observation that MoE routing distributions are highly concentrated: for a given task, only a small subset of experts processes most tokens, and the identity of these experts varies substantially across tasks (Wang et al. 2024). ESFT selectively fine-tunes only the task-relevant experts in place while freezing all other experts and shared modules. This approach substantially reduces training time and storage (reported reductions up to ) while often matching or surpassing full fine-tuning on benchmarks such as GSM8K and MMLU. ESFT also outperforms LoRA-style PEFT baselines in this sparse setting, highlighting that MoE structure enables more natural modular adaptation.
A.3.2 Expert Merging from Independently Trained Branches
Branch-Train-MiX (BTX). Branch-Train-MiX (Sukhbaatar et al. 2024) proposes an explicit expert-merging pipeline that constructs an MoE model from independently trained dense branches. Starting from a dense seed model (e.g., Llama-2 7B), it trains branch models in parallel, where each branch is trained on a domain dataset using a standard language modeling objective. The resulting MoE is assembled by (i) extracting the feed-forward (FFN) weights from each branch and installing them as experts, and (ii) averaging the remaining non-FFN parameters across branches. Finally, an MoE fine-tuning stage learns token-level routing over the assembled experts. This design enables embarrassingly parallel training and demonstrates that experts trained in isolation can be combined into a single model that selects different experts at inference time. Increasing the number of experts increases overall model capacity while keeping the number of active experts fixed, improving the efficiency–capacity tradeoff.
A.3.3 Composable Experts for Private or Federated Settings
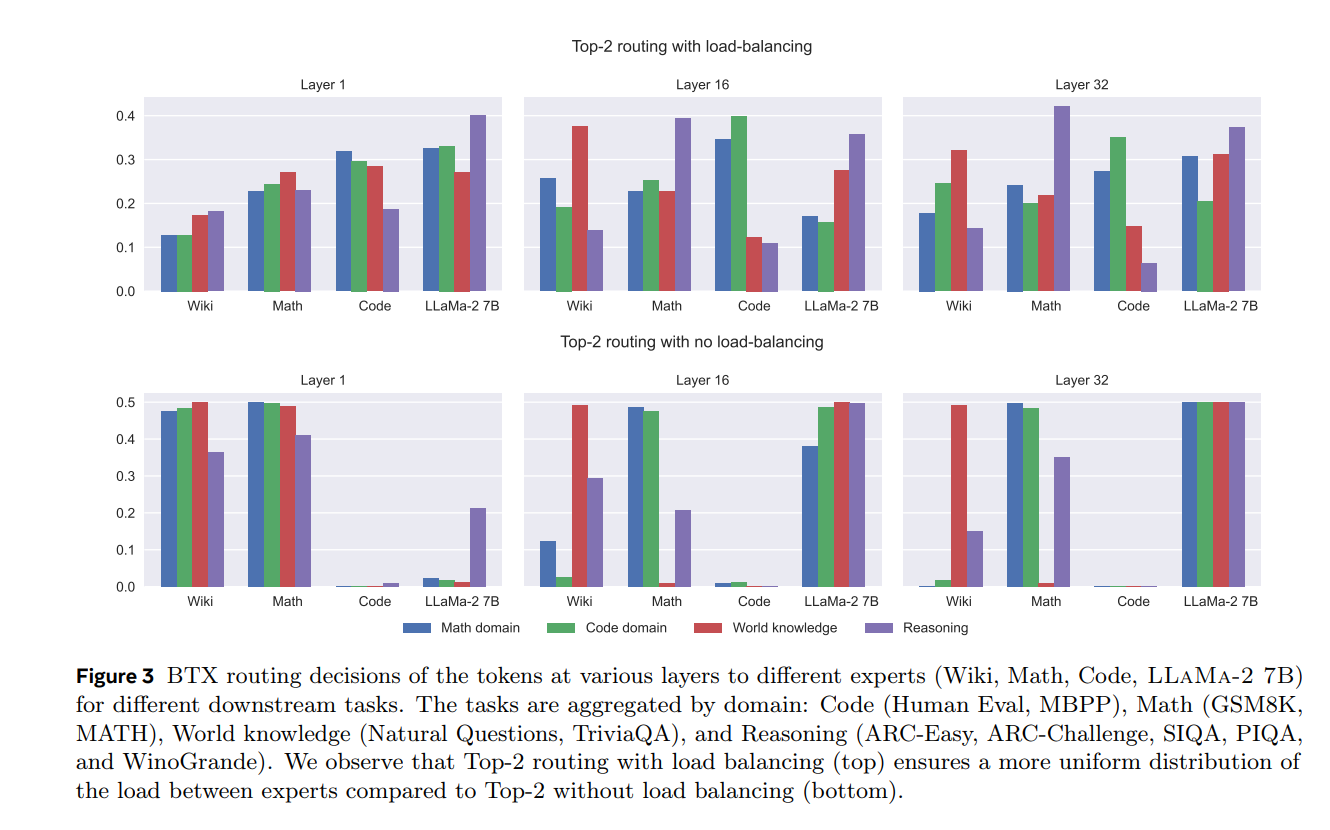
FlexOLMo. FlexOLMo (Shi et al. 2025) proposes an MoE-based framework that enables multiple data owners to train experts independently on private datasets (without data sharing or joint training) and later plug those experts into a single MoE model. A key component is a domain-informed router: experts are trained relative to a shared public anchor , and each expert learns both FFN parameters and a router embedding that reflects which tokens it should handle independently. Because all experts are trained with the same anchor, their router embeddings become comparable across domains, enabling expert opt-in/opt-out at inference without retraining. Empirically, FlexOLMo shows that performance improves as more experts are activated, up to a small number (e.g., four experts), after which gains saturate.
Instead of learning jointly, FlexOLMo decomposes it into expert-specific router embeddings and builds the merged router by concatenating the independently learned rows together with the shared public row :
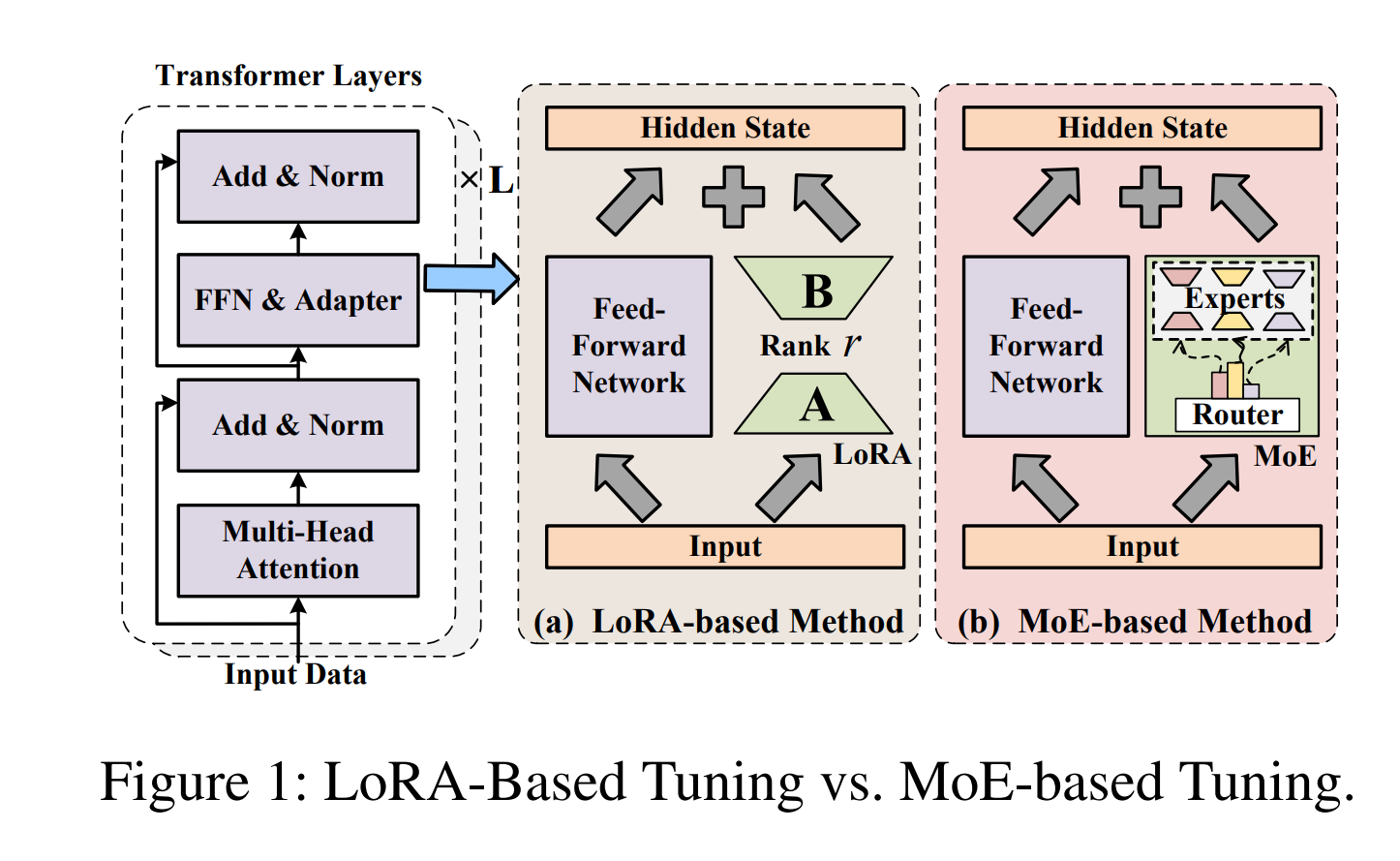
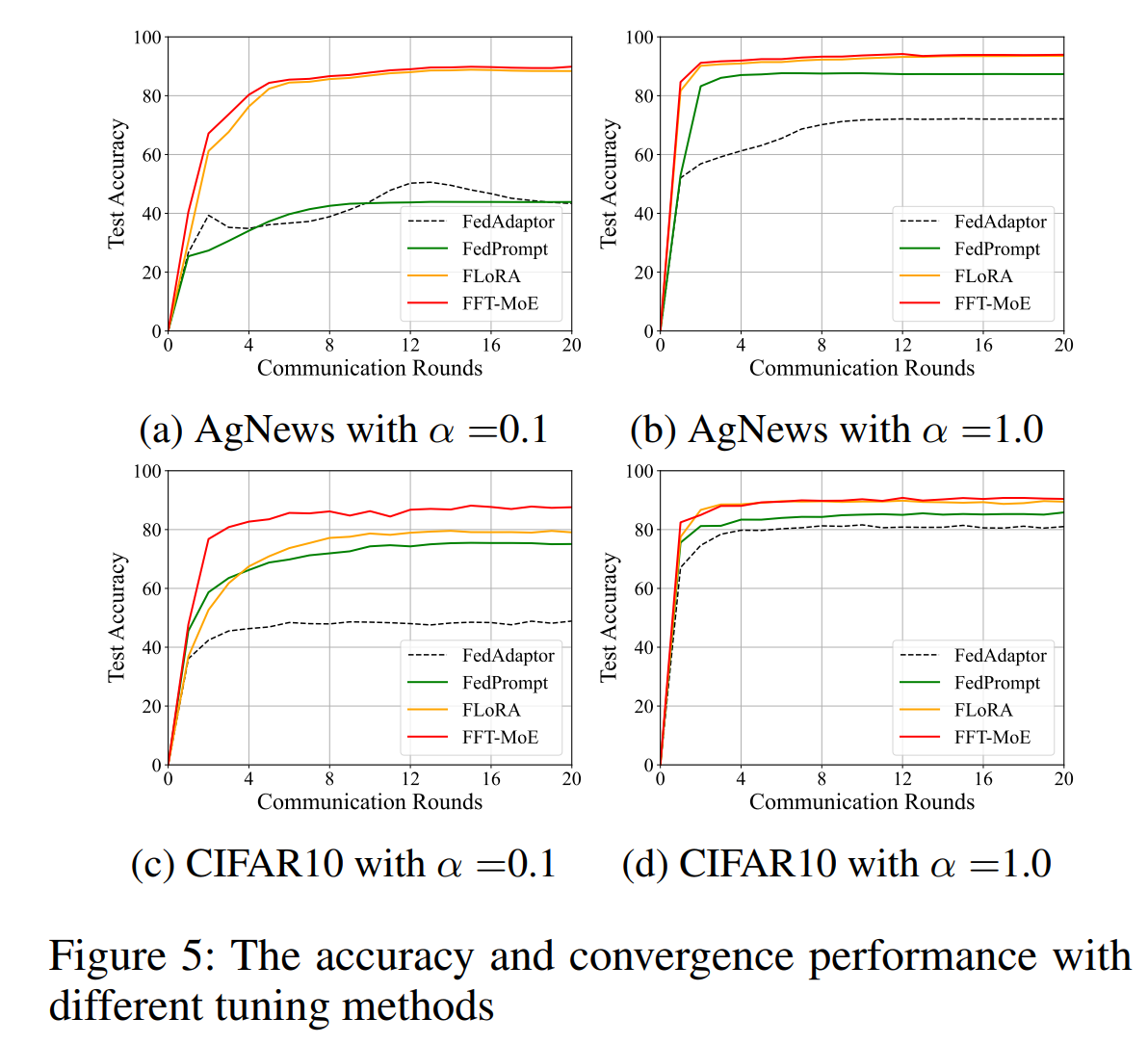
Federated MoE Fine-Tuning (FFT-MoE). FFT-MoE (Gang Hu et al. 2025) extends composable expert adaptation to heterogeneous federated learning. Instead of using LoRA adapters, it inserts sparse MoE adapters into a frozen foundation model. Each client trains a lightweight router to activate a personalized subset of experts, while keeping the overall adapter structure compatible for aggregation. Importantly, FFT-MoE supports heterogeneous compute by allowing clients to choose different sparsity levels : high-capacity clients can activate more experts, while resource-constrained clients activate fewer, without breaking model-size consistency.
A.4 Milestone 3: Practical Interfaces for Expert Composition
Beyond the existence of specialized experts, modular language models may require practical interfaces that enable experts to be reliably selected, combined, and coordinated at inference time. Such interfaces determine how information flows between experts and can take the form of routing mechanisms, learned connector layers, or explicit constraints on expert interaction. When attention parameters are jointly trained or unfrozen, expert composition is not merely a routing problem and often benefits from additional learned structure to harmonize independently trained components. In our setting, however, we do not plan to train or modify the attention layers, and therefore do not require these more complex composition interfaces. Nonetheless, these studies demonstrate that expert composition can be extended beyond routing alone, highlighting a viable path for future expansion should attention-level adaptation become necessary.
A.4.1 Stitching-Based Expert Composition
BTS: Harmonizing Specialized Experts into a Generalist LLM. Branch-Train-Stitch (BTS) presents an alternative to standard MoE routing by introducing a learned stitching layer that connects independently trained experts without token-level routing (Zhang, Bhargava, et al. 2025). In contrast to our approach, BTS fine-tunes both feed-forward and attention parameters. To manage the added complexity of unfreezing attention, BTS relies on intermediate connector layers rather than dynamic per-token expert selection to align and merge expert representations, mitigating mismatches that arise from independent expert training.
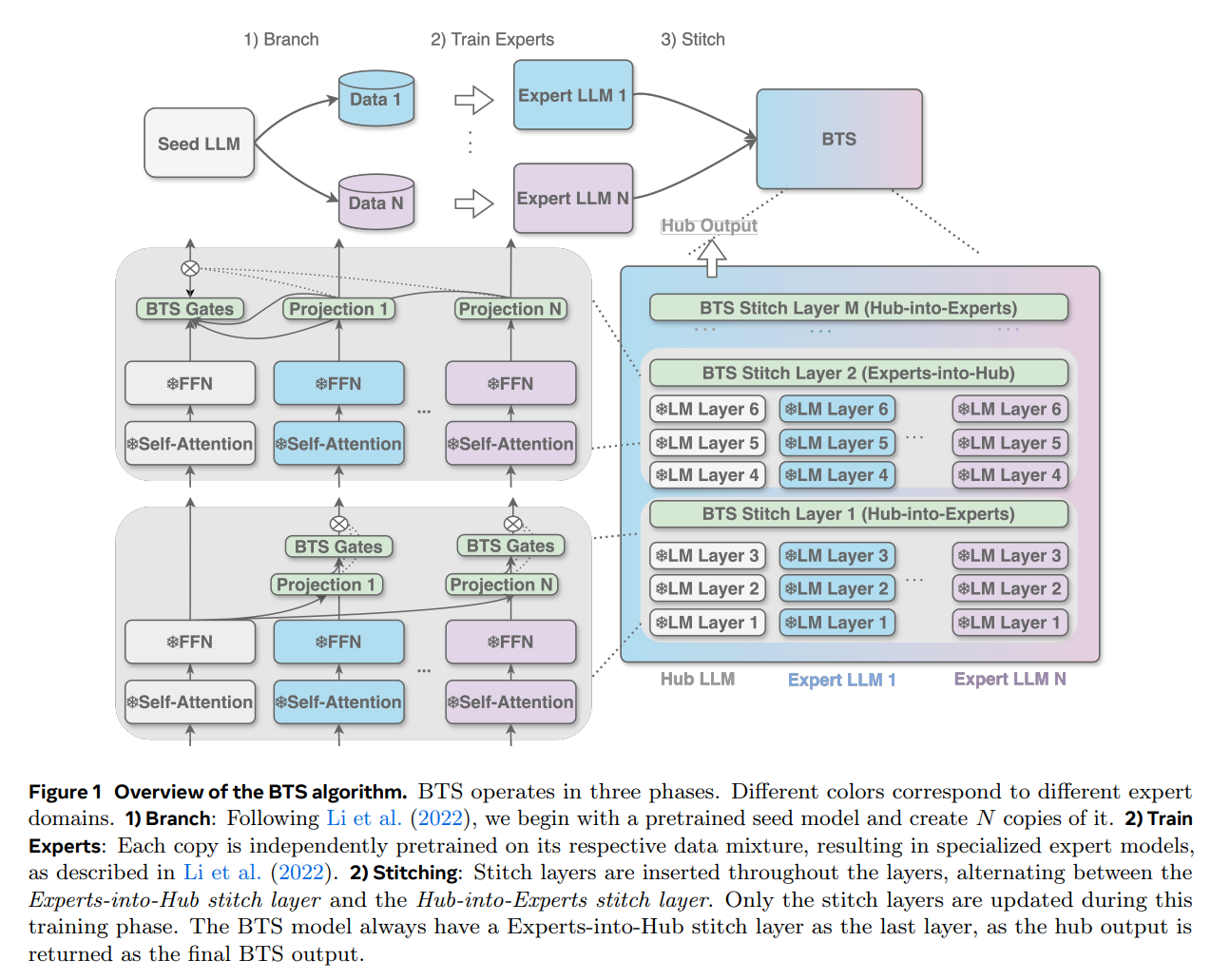
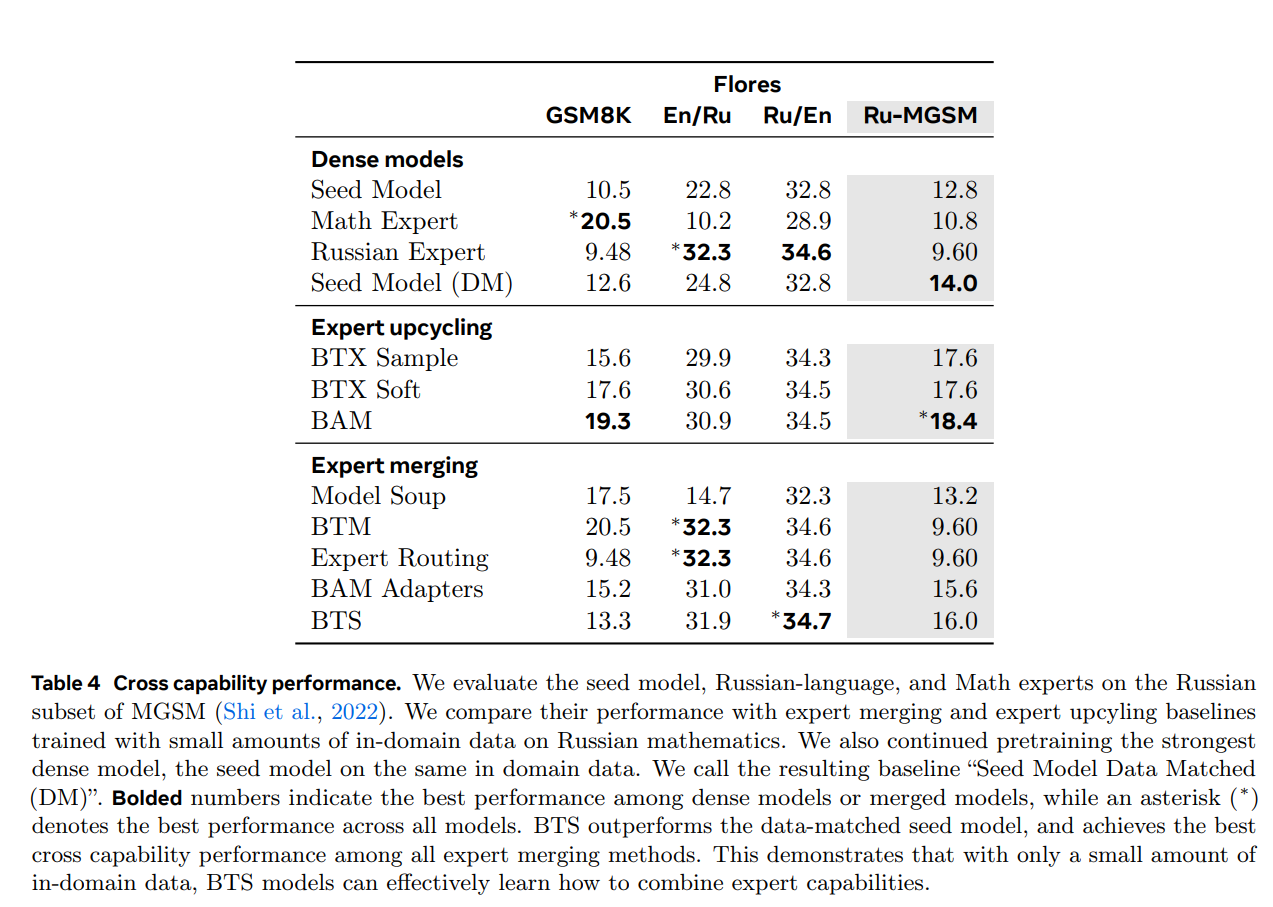
Empirically, BTS achieves the strongest generalist performance among several baselines, including the seed model, individual experts, expert merging, and expert upcycling, and is the only method to outperform all individual experts on certain tasks.
A.4.2 Parameter Upcycling with Learned Connectors
BAM: Parameter Upcycling for Mixture-of-Experts. Cohere's BAM upcycles multiple domain-specialized dense models into a unified MoE by promoting both feed-forward and attention layers to expert modules (Zhang, Gritsch, et al. 2024). During merging, all non-expert parameters are averaged across branches, while expert parameters are preserved. Unlike stitching-based approaches, BAM relies on token-level routing, and the resulting MoE model requires an additional fine-tuning stage to train the router and coordinate the upcycled experts. This design demonstrates that jointly upcycling attention and feed-forward components enables effective expert composition with minimal architectural changes.
A.5 Milestone 4: Expert Lifecycle Management
A final advantage of modular architectures is support for expert lifecycle operations, like expert pruning. These operations enable models to evolve over time while preserving efficiency, controllability, and deployment practicality.
A.5.1 Expert Removal and Data Opt-Out
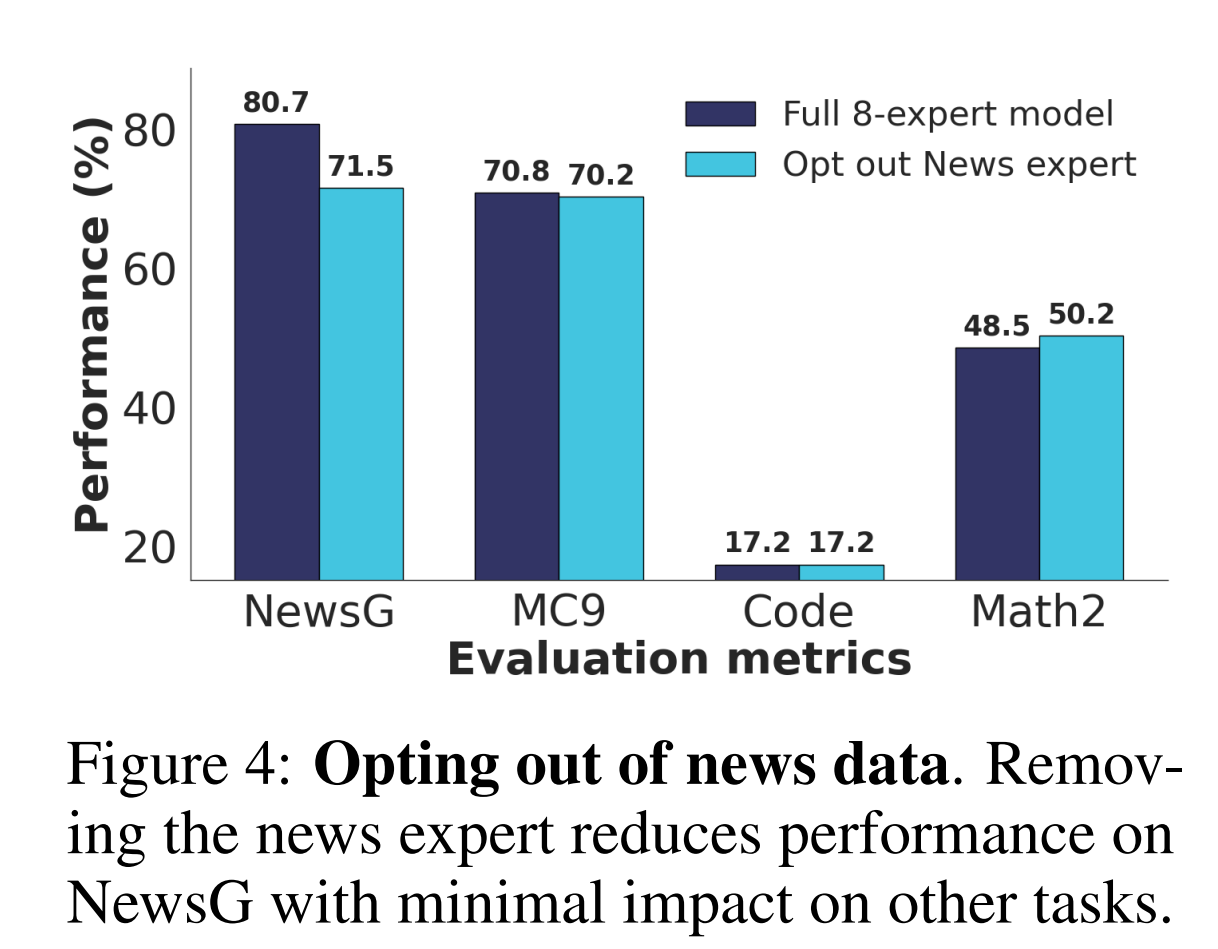
FlexOLMo (Shi et al. 2025) provides a simple mechanism for dataset-level opt-out by allowing experts trained on specific data sources to be removed at inference time. For example, excluding the news expert leads to an expected performance drop on news-related tasks, while performance on unrelated tasks remains largely unchanged. This demonstrates that independently trained experts can be treated as removable modules, enabling controllable specialization and supporting practical data governance constraints.
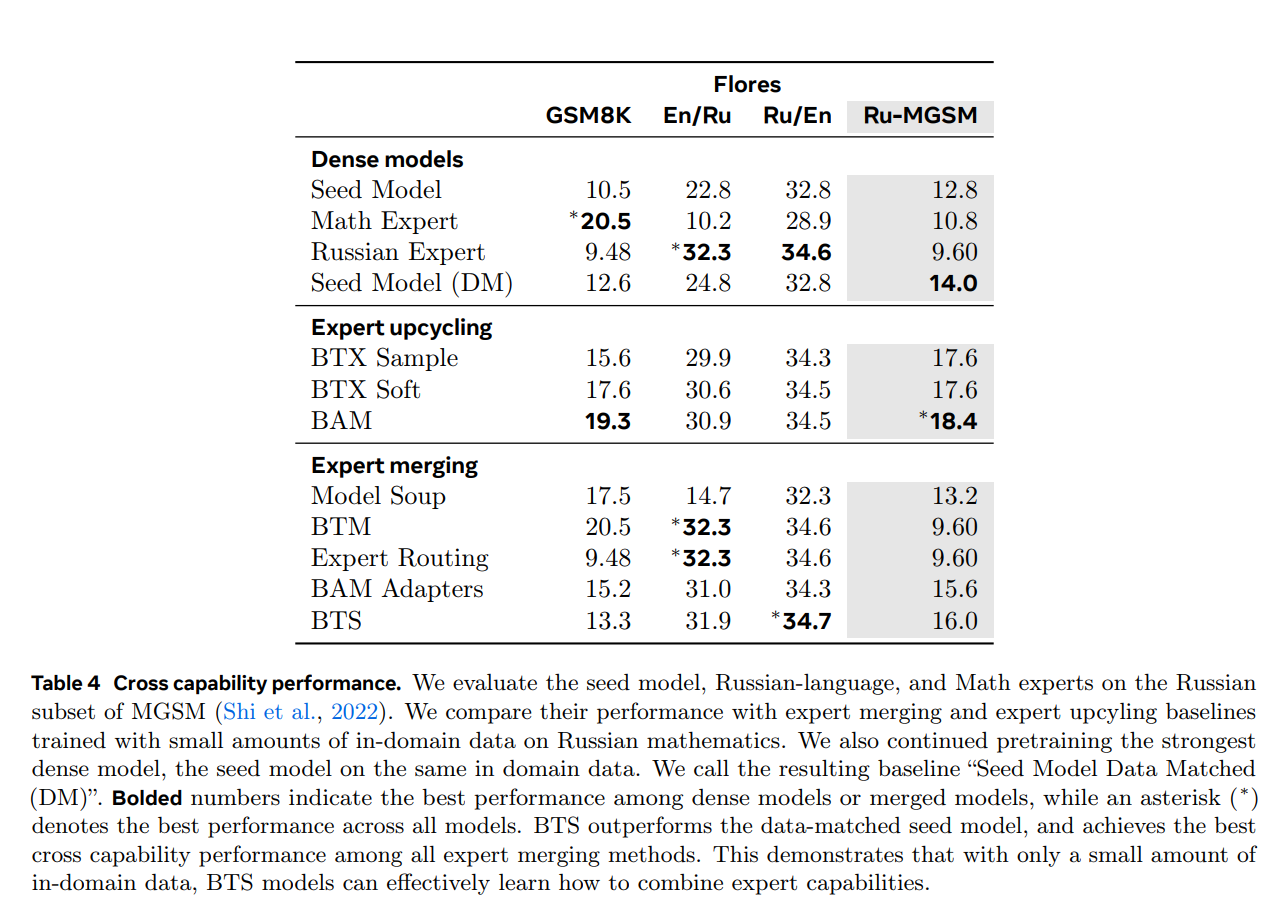
A.5.2 Expert Pruning and Model Densification
Recent work (T. Chen et al. 2022) also shows that MoE models can be pruned into smaller architectures while retaining most of their downstream performance. In task-specific expert pruning, the model is fine-tuned and progressively pruned so that only the most "professional" expert in each MoE layer is retained. After pruning, the resulting single-expert (dense) model preserves approximately 99.3% of the performance of the original full MoE model across multiple downstream tasks, indicating substantial redundancy among experts and supporting efficient expert lifecycle management.