Literature Review: Modular and Composable MoE Systems
Model Modularity in Practice
We organize the literature around five milestones that collectively characterize modular large language models. Milestone 0 establishes the core properties and empirical advantages of MoE architectures. Milestone 1 examines selective adaptation, showing how partial expert updates enable efficient fine-tuning without modifying the full model. Milestone 2 focuses on composable specialization, demonstrating how experts trained on different domains can be combined. Milestone 3 addresses practical interfaces for expert composition, including routing mechanisms and learned connectors. Finally, Milestone 4 explores expert lifecycle management, covering pruning, removal, and replacement of experts.
Milestone 0: Foundational MoE Properties
Shared Expert (Hub)
A common design pattern in MoE models is to include a shared expert: a dense MLP (or a small set of experts) applied to all tokens, in addition to the sparsely routed experts. This "shared + routed" structure improves training stability and preserves general-purpose representations while allowing routed experts to specialize.
Residual-MoE (Rajbhandari et al., 2022) proposes a design where each MoE layer consists of a fixed dense MLP (the shared expert) together with a sparse set of routed experts. For each token, the model computes the shared expert output and the output of a single routed expert selected by the router, then combines them additively in a residual-style form. The dense pathway provides a stable general representation, while the routed expert acts as an "error-correction" term.
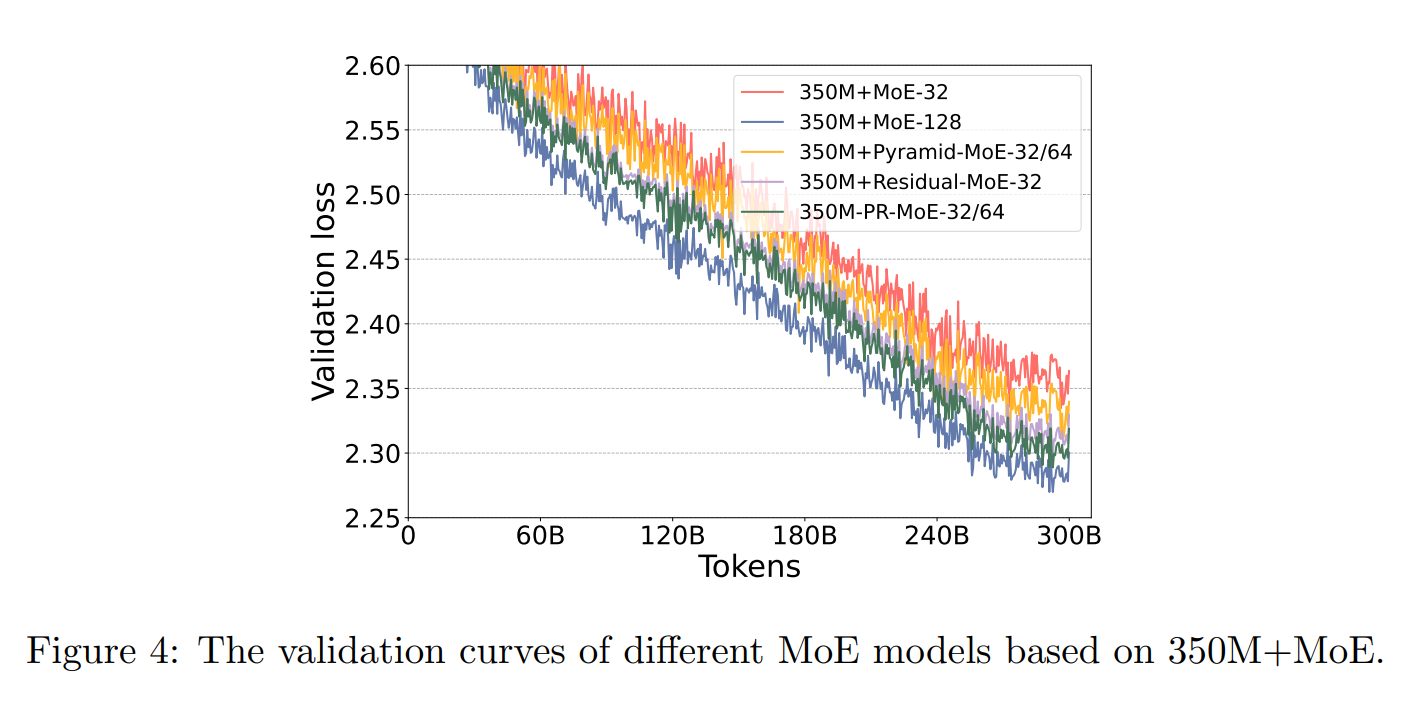
Residual MoE-32 (gray), which uses a shared expert and a routed expert, is significantly more parameter-efficient than standard MoE-32 (red) with top-2 expert selection (Rajbhandari et al., 2022).
DeepSeekMoE (Dai et al., 2024) generalizes this through Shared Expert Isolation, where multiple shared experts are always activated to separate common knowledge from specialized capacity. Each MoE layer designates experts as shared experts activated for every token, independent of the router. The remaining experts are treated as routed specialists, reducing redundancy and encouraging specialization.
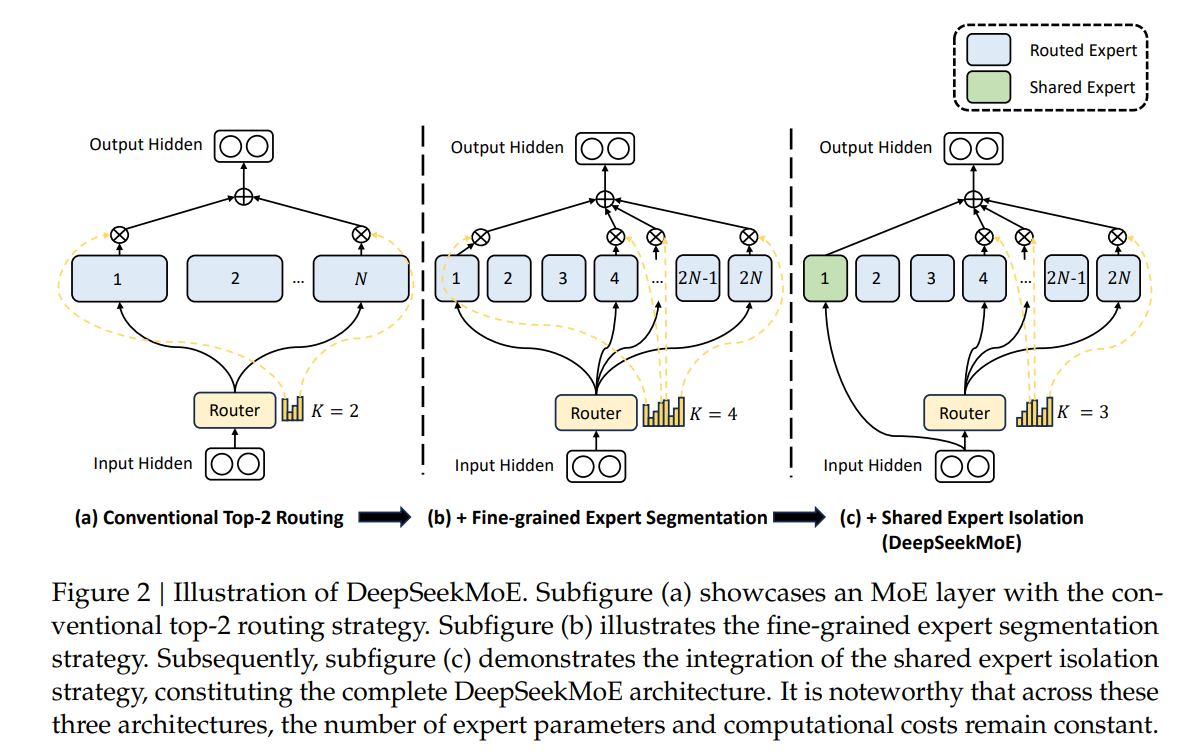
DeepSeekMoE architecture: (a) conventional top-2 routing, (b) fine-grained expert segmentation, (c) shared expert isolation. Parameter count and compute cost remain constant across all three (Dai et al., 2024).
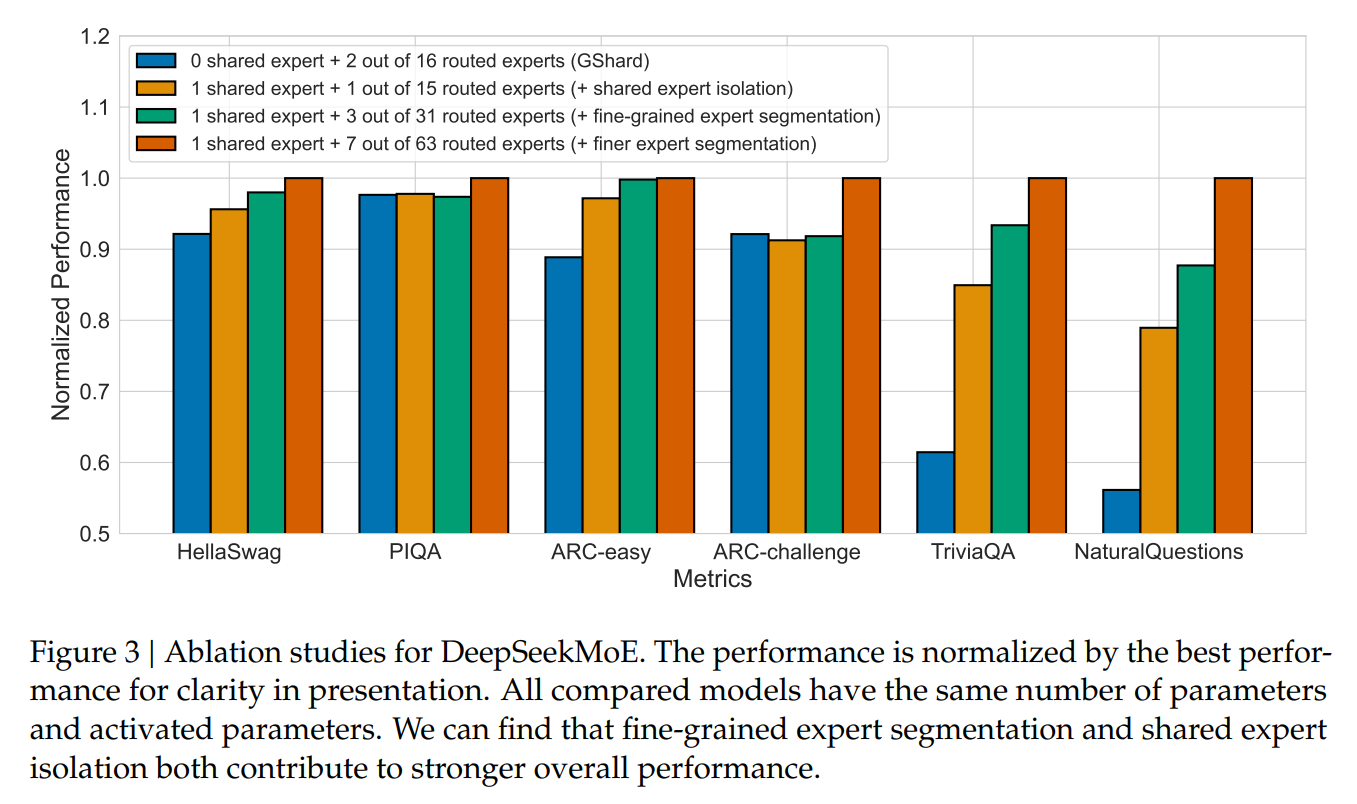
Ablation studies for DeepSeekMoE. Fine-grained expert segmentation and shared expert isolation both contribute to stronger overall performance (Dai et al., 2024).
The Role of Experts in LLMs
Recent work analyzes router behavior in MoE models to characterize expert roles. Hu et al., 2026 identifies two primary roles: domain experts (detected via entropy-based specialization metrics) and driver experts (identified via causal-effect metrics that perturb routing probabilities).
Empirical results show that only a small fraction of experts exhibit strong domain specialization, while most experts display weak or negligible domain-specific behavior. Increasing router weights for identified domain and driver experts improves accuracy across models. The identification of driver experts is essential to Connito's approach, as it helps identify and build up the required shared experts from a model.
Low Expert Utilization
Several studies examine how experts are utilized during inference and find that MoE models rely on a small subset of experts. Yuan et al., 2025 analyzed routing distributions across domains and traced expert contributions to the residual stream using early decoding, showing that a single expert is often sufficient to approximate next-token prediction outputs. Similar low utilization is observed in Wang et al., 2024.
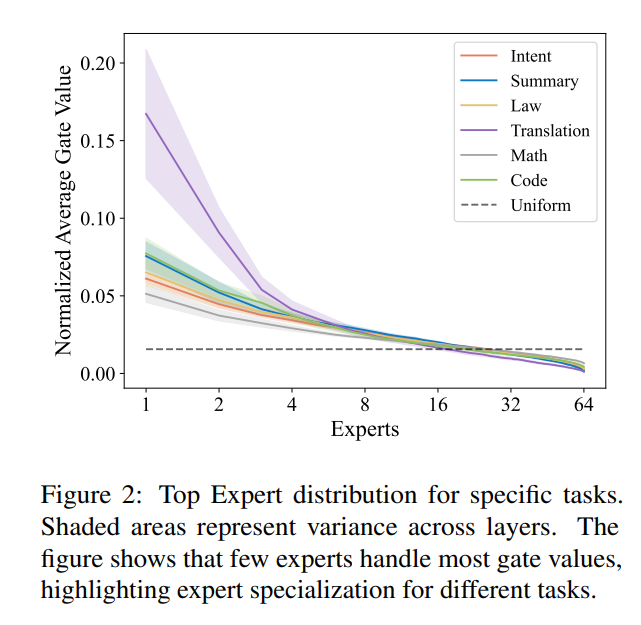
Expert routing concentration per task (Wang et al., 2024). A small number of experts capture most gate values across all domains.
This result is important because it suggests that fine-tuning and inference often do not require the full set of experts, enabling simpler, lower-cost distributed training designs with reduced overhead.
Relationships Between Experts
Further analyses from Wang et al., 2024 explore relationships between experts by examining co-activation and routing correlations within MoE layers. The results reveal structured patterns of redundancy and cooperation, where subsets of experts exhibit correlated behavior while others act more independently.
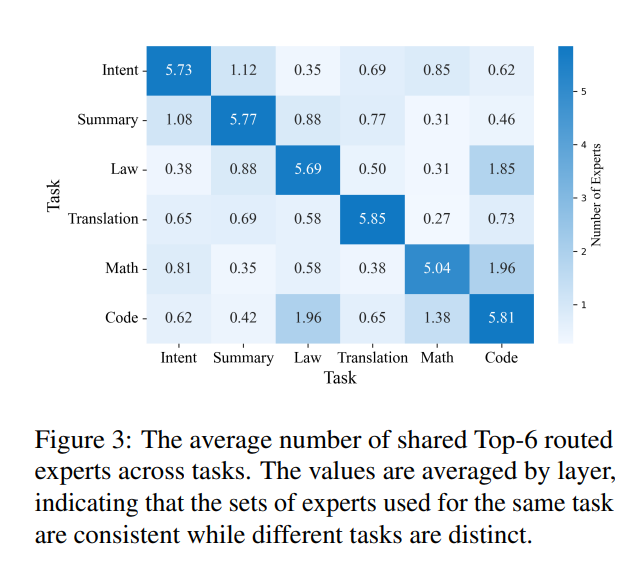
Average number of shared Top-6 routed experts across tasks (Wang et al., 2024). Expert sets used for the same task are consistent while different tasks are distinct.
Understanding these relationships reveals expert redundancy and specialization boundaries, which can guide structured pruning, expert merging, and model compression.
Milestone 1: Selective Adaptation via Partial Expert Updates
A defining advantage of modular architectures is their ability to adapt by updating only a subset of parameters — typically experts or routing components — rather than fine-tuning the entire model. Prior work shows that selectively adapting experts can improve domain specialization, reduce interference between tasks, and significantly lower training cost.
Domain Adaptation via Routing & Gradient Control
Dynamic Expert Specialization (DES-MoE) (Li et al., 2025) studies multi-domain adaptation under catastrophic forgetting and proposes mechanisms that encourage domain specialization while minimizing interference across domains. It introduces an Adaptive Lightweight Router (ALR) trained with a distillation objective, which keeps the fine-tuned router close to the pretrained routing behavior early in training and gradually allows domain-specific routing as adaptation proceeds.
In addition, DES-MoE builds an expert-domain correlation map by tracking expert activation frequencies during a warm-up phase, then masks gradients so that domain updates primarily modify experts most associated with that domain.
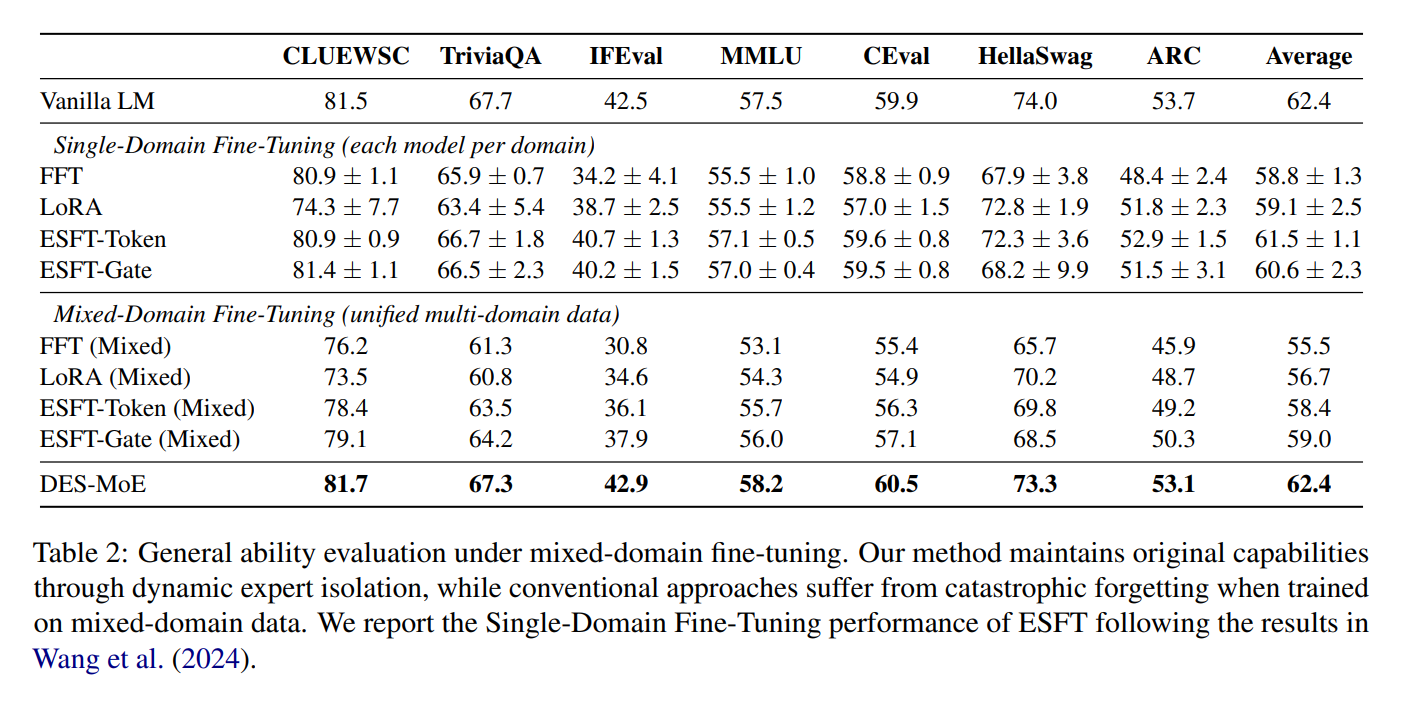
General ability evaluation under mixed-domain fine-tuning (Li et al., 2025). DES-MoE maintains original capabilities through dynamic expert isolation, while conventional approaches suffer from catastrophic forgetting.
Dynamic Routing
Expert Choice Routing (Zhou et al., 2022) redefines the routing paradigm by allowing each expert to select its top- tokens, instead of requiring each token to choose a fixed number of experts. This design eliminates load imbalance and provides experts with predictable work allocation. Empirically, it achieves more than 2x faster training convergence than Switch (top-1) and GShard (top-2) routing under the same compute budget.
Milestone 2: Composable Expert Specialization
A second defining property of modular architectures is compositionality: experts trained independently on different domains can be combined to improve performance on the union of those domains, without retraining a single monolithic model.
Task-Specific Expert Selection & Reuse
Expert-Specialized Fine-Tuning (ESFT) (Wang et al., 2024) is motivated by the observation that MoE routing distributions are highly concentrated: for a given task, only a small subset of experts processes most tokens, and the identity of these experts varies substantially across tasks. ESFT selectively fine-tunes only the task-relevant experts in place while freezing all other experts and shared modules. This approach substantially reduces training time and storage (reported reductions up to ~90%) while often matching or surpassing full fine-tuning on benchmarks such as GSM8K and MMLU.
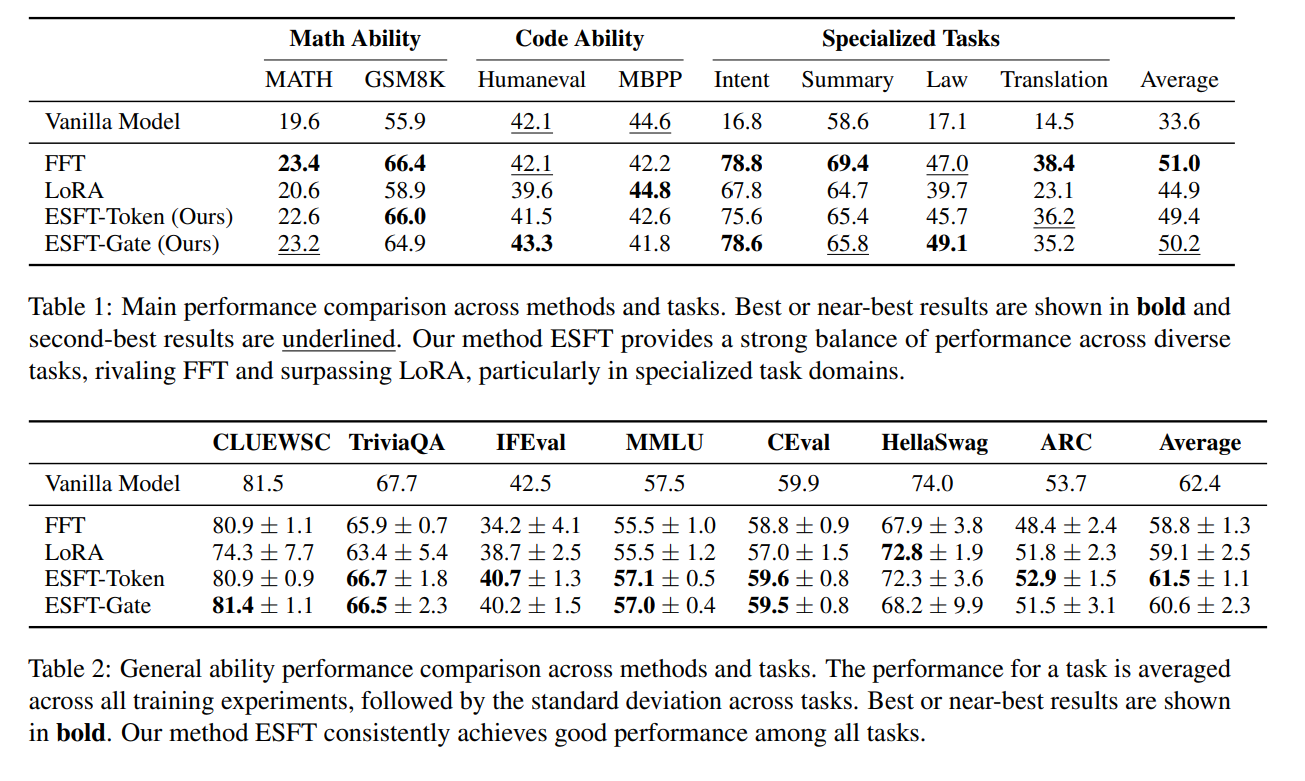
ESFT matches or surpasses full fine-tuning across math, code, and specialized tasks while training far fewer parameters (Wang et al., 2024).
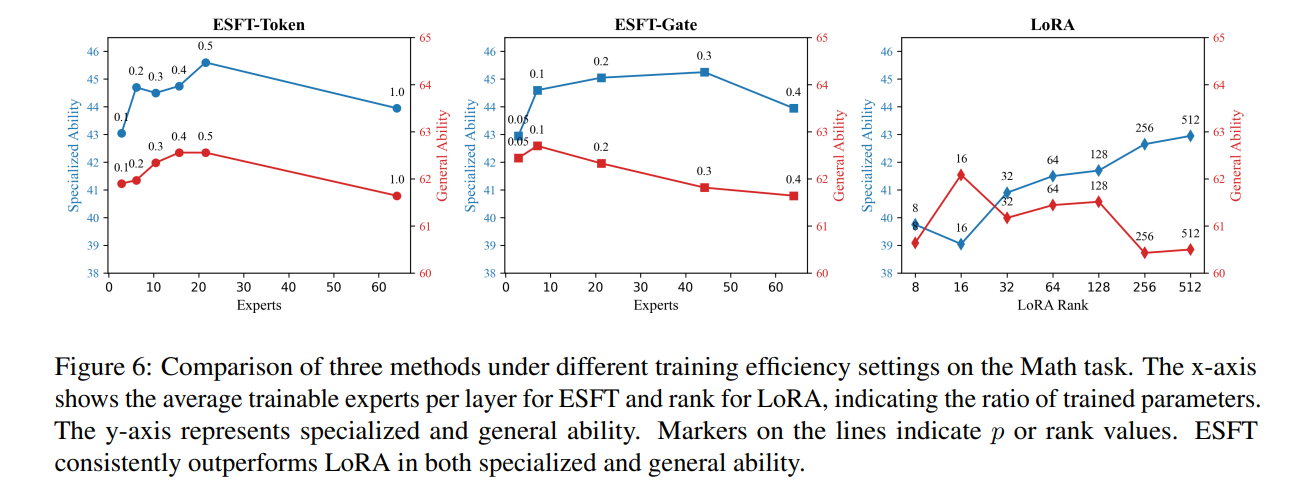
ESFT outperforms LoRA in both specialized and general ability as expert count increases (Wang et al., 2024).
Merging Experts from Independently Trained Branches
Branch-Train-MiX (BTX) (Sukhbaatar et al., 2024) proposes an explicit expert-merging pipeline that constructs an MoE model from independently trained dense branches. Starting from a dense seed model (e.g., Llama-2 7B), it trains branch models in parallel on domain datasets. The resulting MoE is assembled by extracting the feed-forward weights from each branch as experts, averaging the remaining non-FFN parameters, and fine-tuning a router to coordinate expert selection.
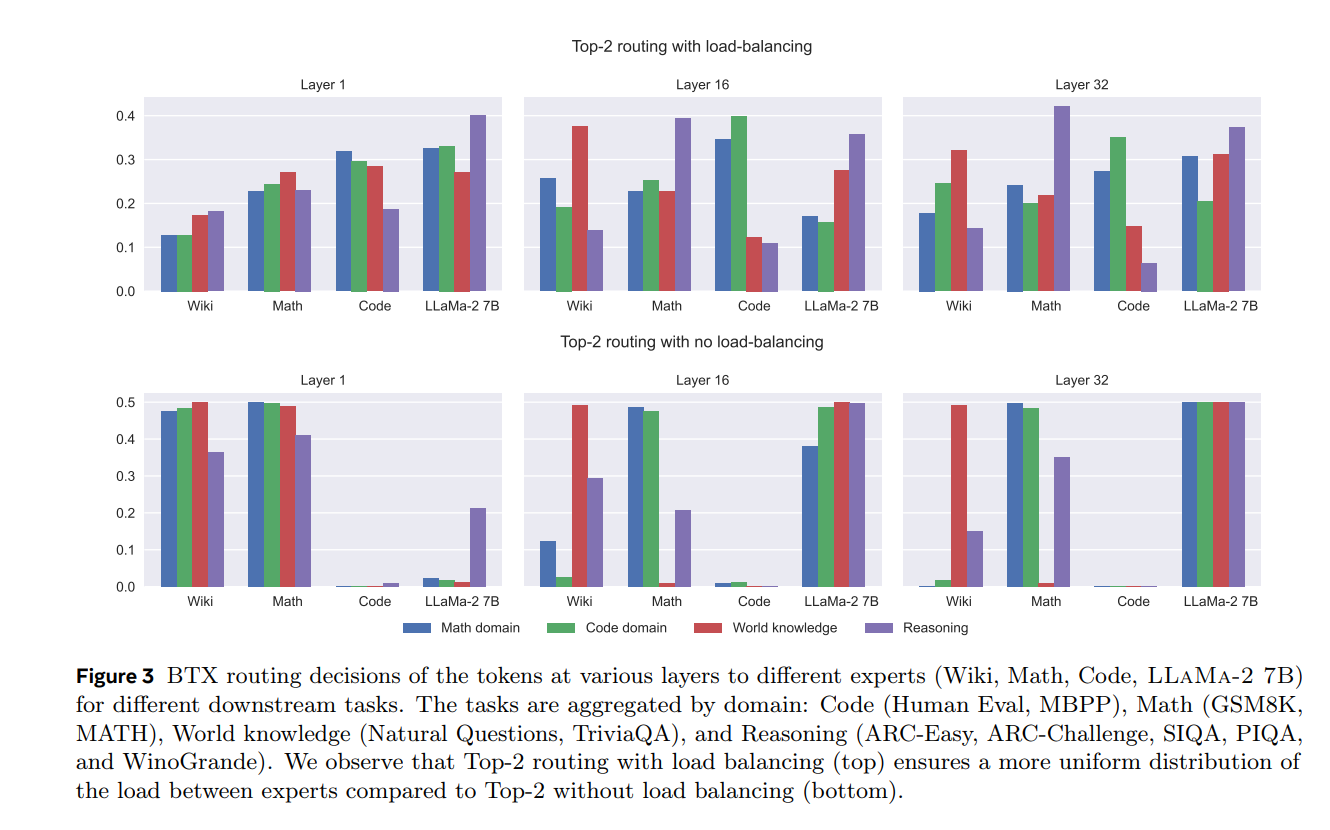
BTX routing across layers for different tasks (Sukhbaatar et al., 2024). Even when experts are trained independently on disjoint domains, experts from other domains are automatically utilized.
Composable Experts for Federated & Private Settings
FlexOLMo (Shi et al., 2025) enables multiple data owners to train experts independently on private datasets and later plug those experts into a single MoE model. Experts are trained relative to a shared public anchor, and each expert learns both FFN parameters and a router embedding, enabling expert opt-in/opt-out at inference without retraining.
FFT-MoE (Hu et al., 2025) extends composable expert adaptation to heterogeneous federated learning. Instead of using LoRA adapters, it inserts sparse MoE adapters into a frozen foundation model. Each client trains a lightweight router to activate a personalized subset of experts.
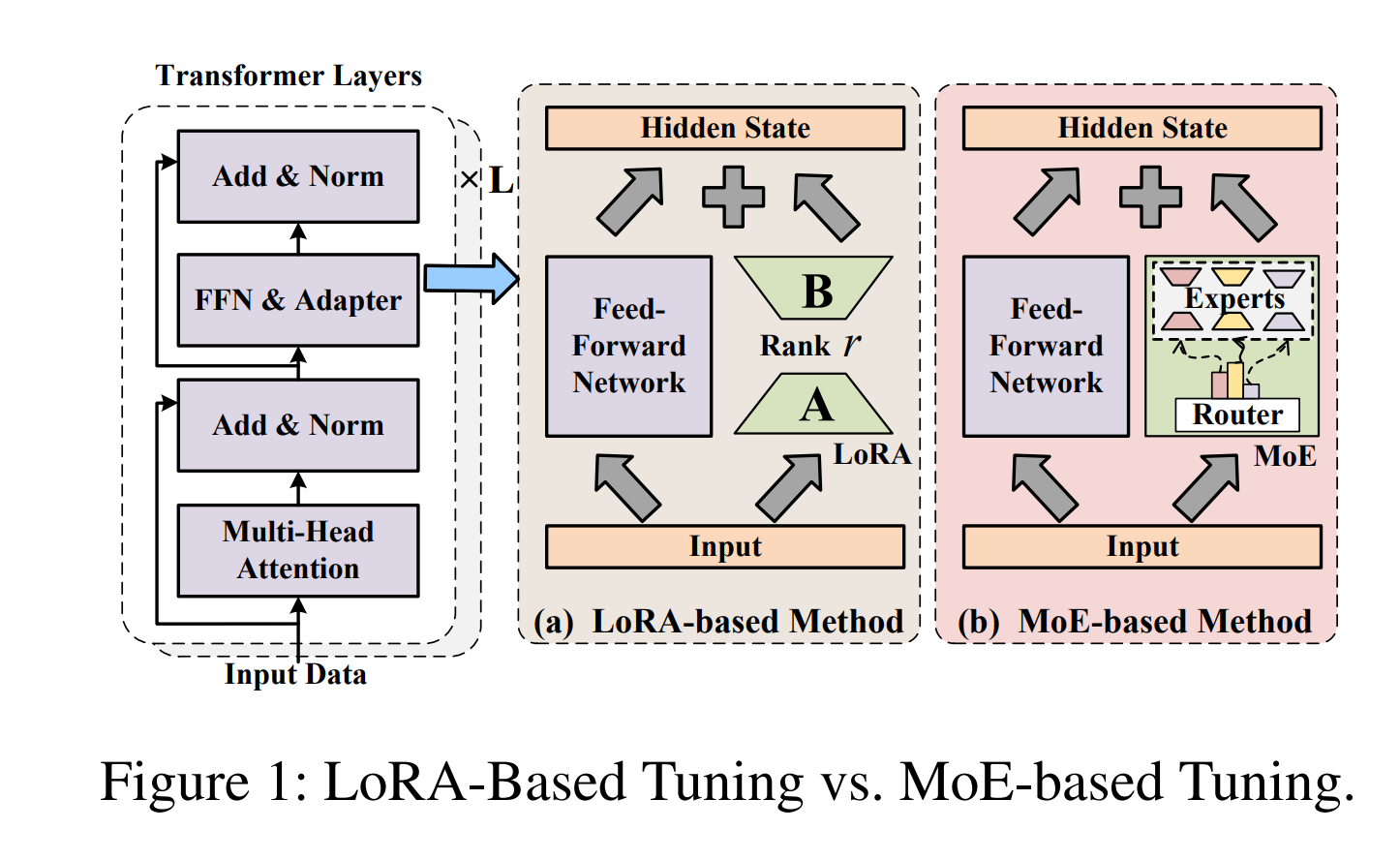
LoRA-based tuning vs MoE-based tuning (Hu et al., 2025). MoE adapters support heterogeneous compute by allowing different sparsity levels per client.
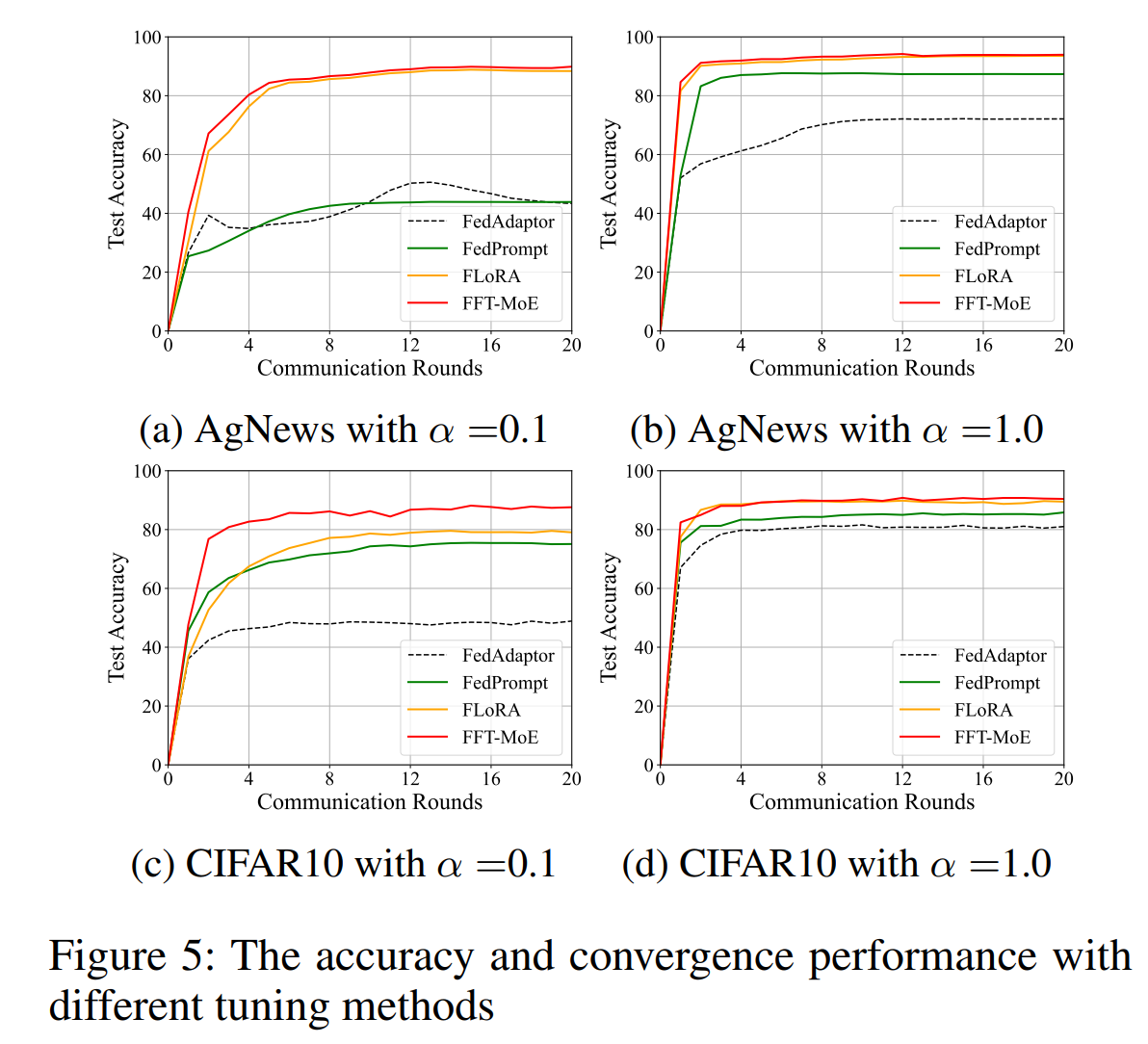
FFT-MoE achieves higher accuracy and faster convergence than LoRA, FedAdaptor, and FedPrompt across datasets (Hu et al., 2025).
Milestone 3: Practical Composition Interfaces
Beyond the existence of specialized experts, modular language models may require practical interfaces that enable experts to be reliably selected, combined, and coordinated at inference time. When attention parameters are jointly trained or unfrozen, expert composition is not merely a routing problem and often benefits from additional learned structure.
In Connito's setting, we do not plan to train or modify the attention layers, and therefore do not require these more complex composition interfaces. Nonetheless, these studies demonstrate that expert composition can be extended beyond routing alone.
Stitching-Based Expert Composition
BTS (Branch-Train-Stitch) (Zhang, Bhargava et al., 2025) introduces a learned stitching layer that connects independently trained experts without token-level routing. BTS fine-tunes both feed-forward and attention parameters, relying on intermediate connector layers to align and merge expert representations.
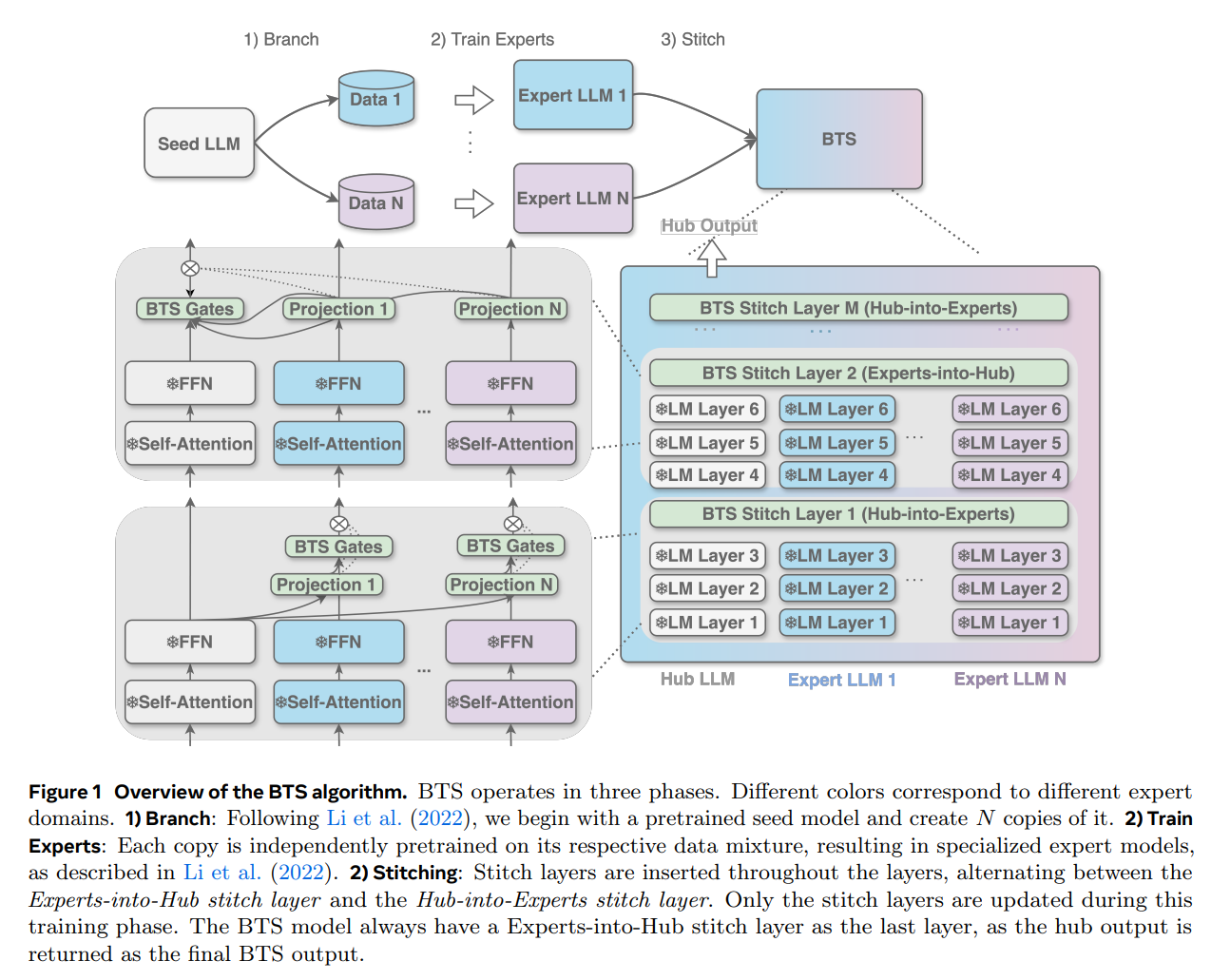
BTS operates in three phases: Branch (create copies), Train Experts (independent pretraining), and Stitch (insert learned stitch layers). Only stitch layers are updated during the final phase (Zhang et al., 2025).
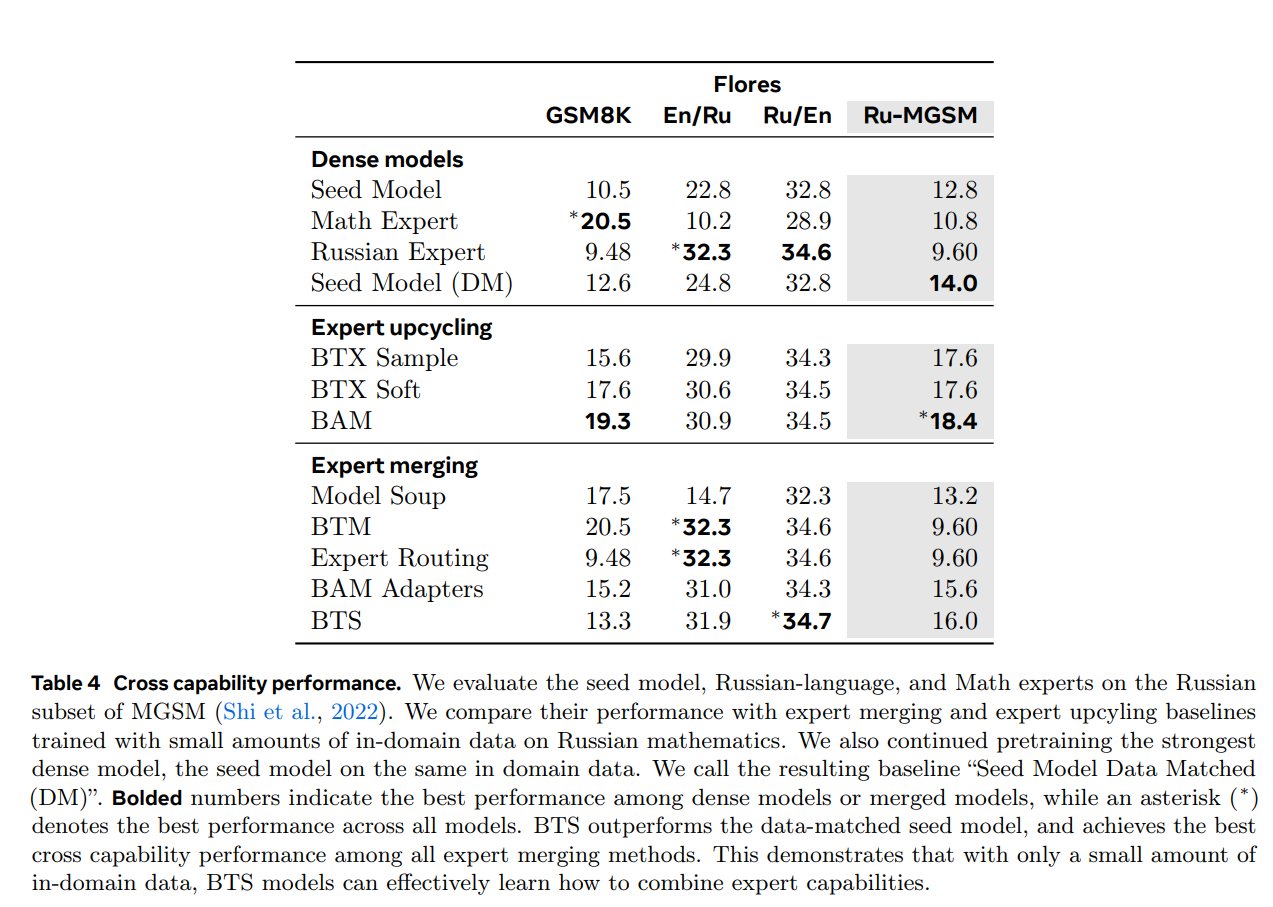
BTS outperforms the data-matched seed model and achieves the best cross capability performance among all expert merging methods (Zhang et al., 2025).
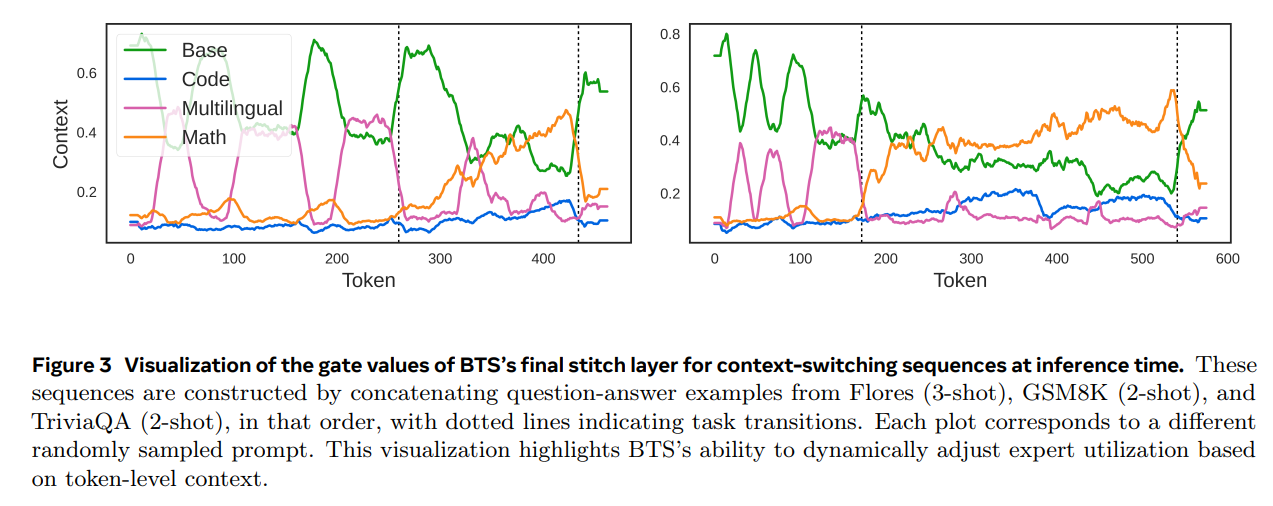
BTS gate values during context-switching sequences. The model dynamically adjusts expert utilization based on token-level context (Zhang et al., 2025).
Parameter Upcycling with Learned Connectors
BAM (Zhang, Gritsch et al., 2024) upcycles multiple domain-specialized dense models into a unified MoE by promoting both feed-forward and attention layers to expert modules. During merging, all non-expert parameters are averaged across branches, while expert parameters are preserved. The resulting MoE model requires an additional fine-tuning stage to train the router and coordinate the upcycled experts.
Milestone 4: Expert Lifecycle Management
A final advantage of modular architectures is support for expert lifecycle operations, including expert removal and pruning. These operations enable models to evolve over time while preserving efficiency, controllability, and deployment practicality.
Expert Removal & Data Opt-Out
FlexOLMo (Shi et al., 2025) provides a mechanism for dataset-level opt-out by allowing experts trained on specific data sources to be removed at inference time. Excluding the news expert leads to an expected performance drop on news-related tasks, while performance on unrelated tasks remains largely unchanged.
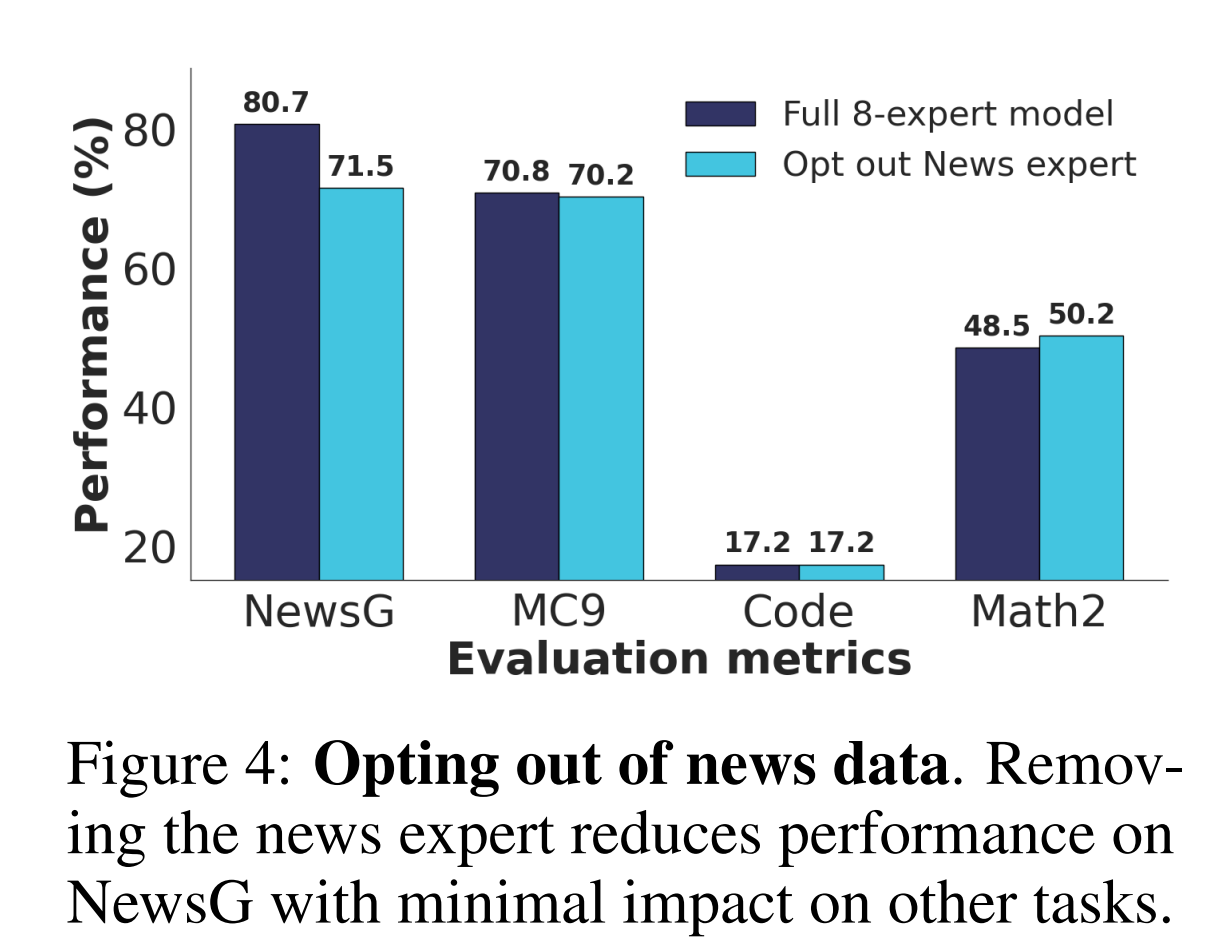
Removing the news expert drops news performance while other tasks remain unaffected (Shi et al., 2025).
Expert Pruning & Densification
Recent work (Chen et al., 2022) shows that MoE models can be pruned into smaller architectures while retaining most of their downstream performance. The model is fine-tuned and progressively pruned so that only the most "professional" expert in each MoE layer is retained.
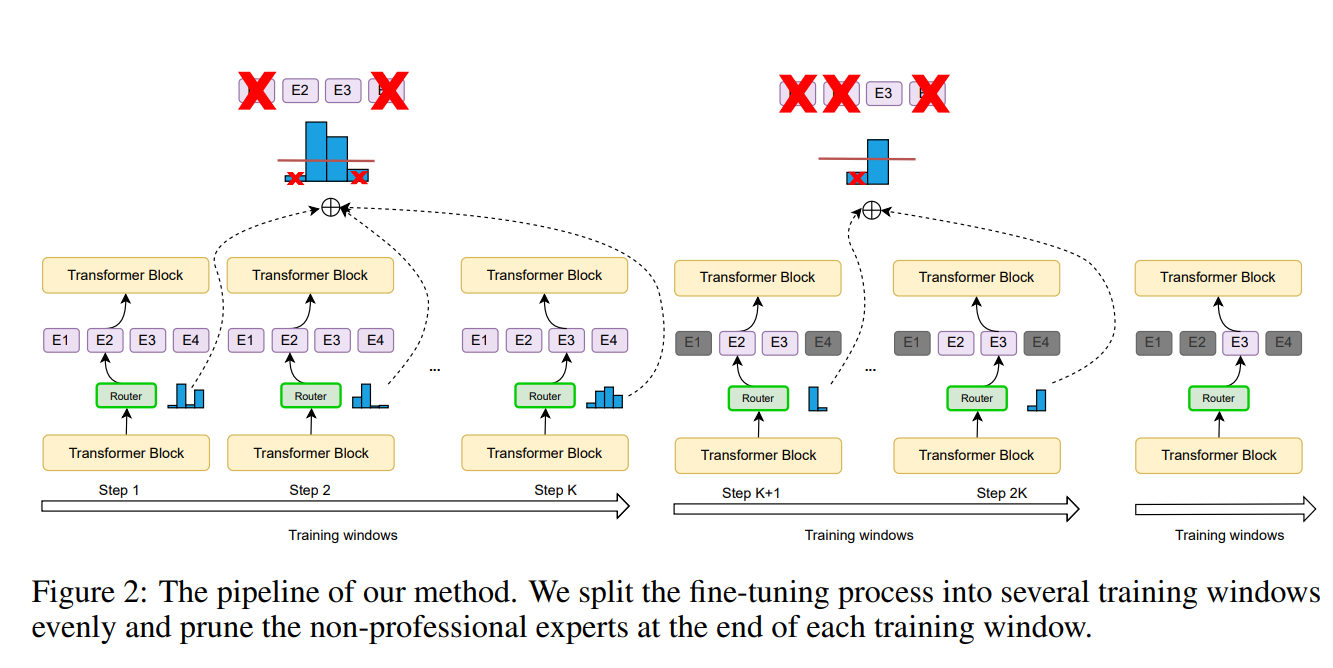
Progressive expert pruning pipeline: non-professional experts are pruned at the end of each training window (Chen et al., 2022).
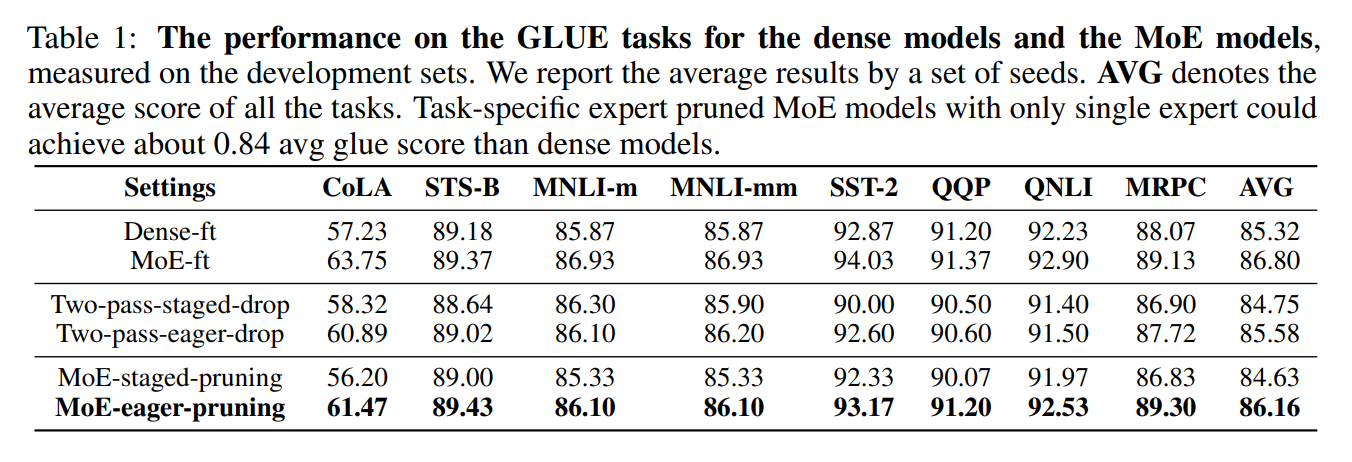
Task-specific expert pruned MoE models with only a single expert achieve about 0.84 avg GLUE score compared to dense models (Chen et al., 2022).
Together, these results highlight that experts can be added, removed, or compressed over time, enabling long-term model evolution with manageable cost.