The Solution: Modular Experts
Connito is a decentralized training platform built on Bittensor that turns customer data into production-ready, domain-specific AI. The approach has two parts: make the models smaller by extracting only the experts you need, then make the library bigger by feeding every result back into a shared, compounding collection.
Smaller Models: Extract & Fine-Tune Experts
Large MoE models like Llama 4 Maverick contain hundreds of expert modules, but for any given domain task only a handful are relevant. Instead of fine-tuning the entire model, Connito extracts the relevant expert subset from the base model and distributes just those experts to miners for training.
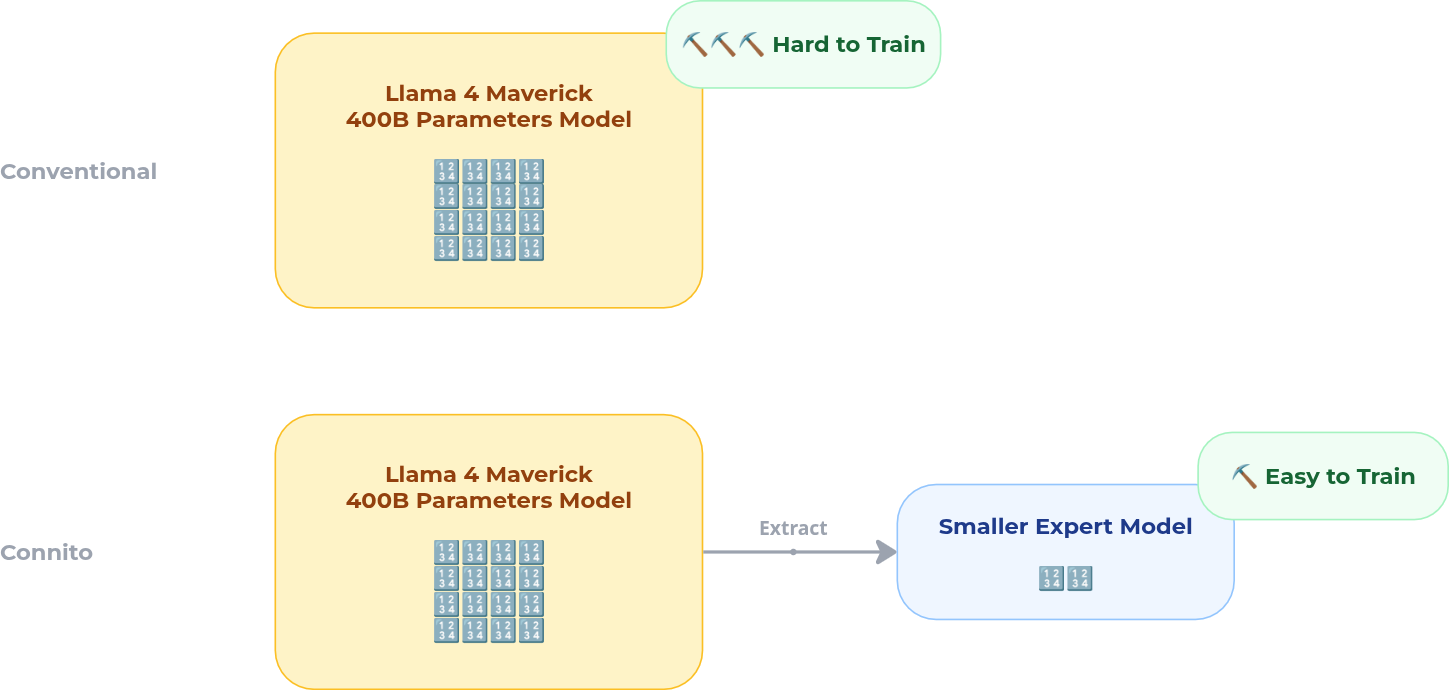
This means:
- Miners only need to hold a fraction of the model — mid-tier GPUs can participate, not just datacenter hardware
- Training is faster — fewer parameters to update, tighter convergence
- No catastrophic forgetting — the rest of the model is untouched; only the targeted experts are modified
The subnet owner identifies which experts to extract based on the customer's domain and data. Miners fine-tune those experts locally, then submit their updates. Validators score quality using Proof-of-Loss, and only the best contributions get merged.
Bigger Library: Compound Every Engagement
Once a fine-tuned expert clears validation, it is added back into an expert library permanently. This is where the compounding effect kicks in:
- The next customer who needs something similar starts from a stronger baseline
- Over time, the library covers more domains at higher quality
- Each engagement makes the system better for every future engagement
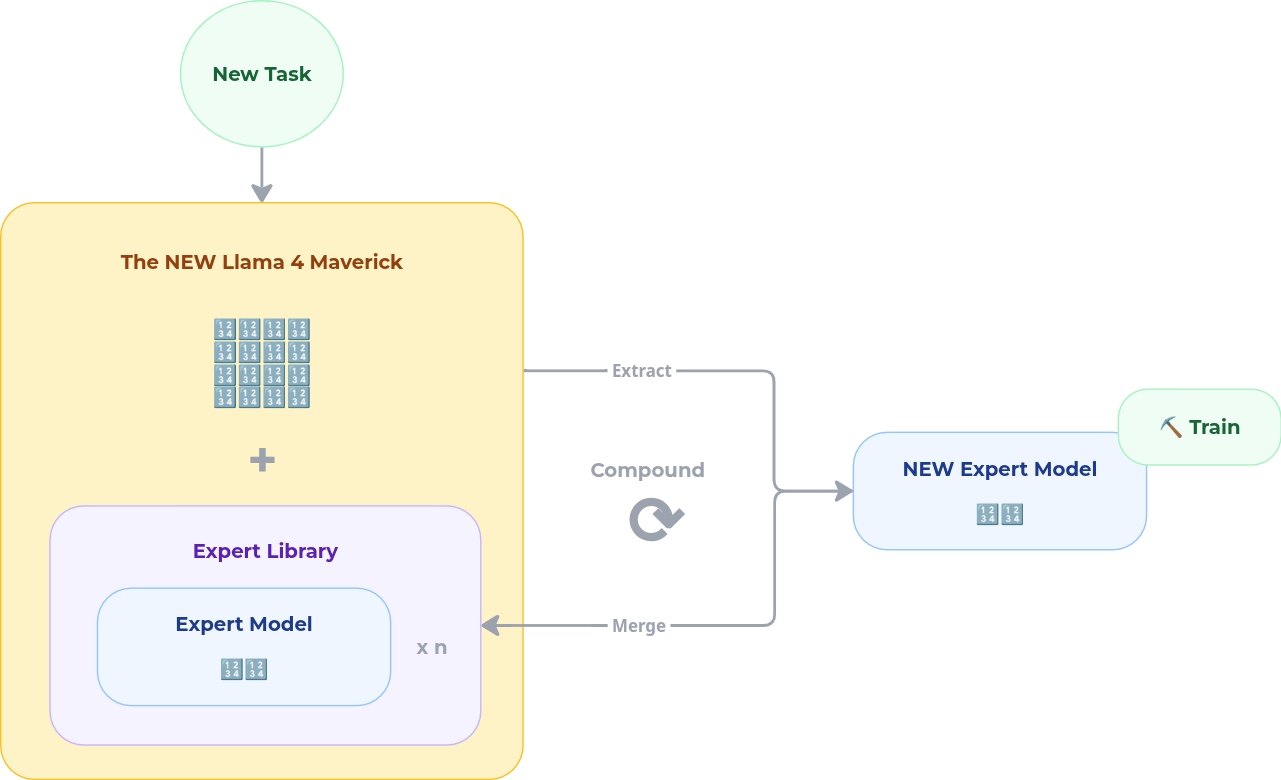
Four Value Propositions
1. Compounding Expert Library
Each training job is not a one-off event — it is a deposit into a growing library of high-quality MoE experts. Experts covering domains like mathematical reasoning, financial risk, healthcare operations, and fraud detection are stored, indexed, and made available for future jobs. New customers start from proven, high-performing building blocks rather than paying to reinvent the same capability from scratch.
The compounding effect is real: as the library deepens, the gap between "what a new customer needs" and "what we already have" narrows. Time-to-value drops. Baseline quality rises. Cost falls. Each customer engagement makes the system better for the next one.
2. Lower Cost, No ML Team
Hiring ML engineers is expensive ($200k–$500k/yr per person), slow (6–18 months to hire and onboard), and requires management overhead most mid-size companies don't have. Consulting firms like Accenture charge $280/hr and layer on coordination costs that often exceed the actual delivery value.
Connito taps the Bittensor talent pool — a globally distributed network of miners and validators — to provide expert-level ML execution on demand. Customers get customization without building an ML organization.
3. Faster Time-to-Production
Distributed MoE training parallelizes work across specialists and retrains only the parameters that matter. Traditional fine-tuning of a large model can take months to set up and iterate. Connito cuts that to days or weeks by narrowing the training target through expert selection and running updates concurrently across the subnet.
4. Right-Sized Deployment
MoE modularity means customers deploy only the experts they need. A customer running inference in a regulated environment does not need to host a 400B parameter model — they can run the relevant expert subset at a fraction of the cost and footprint.
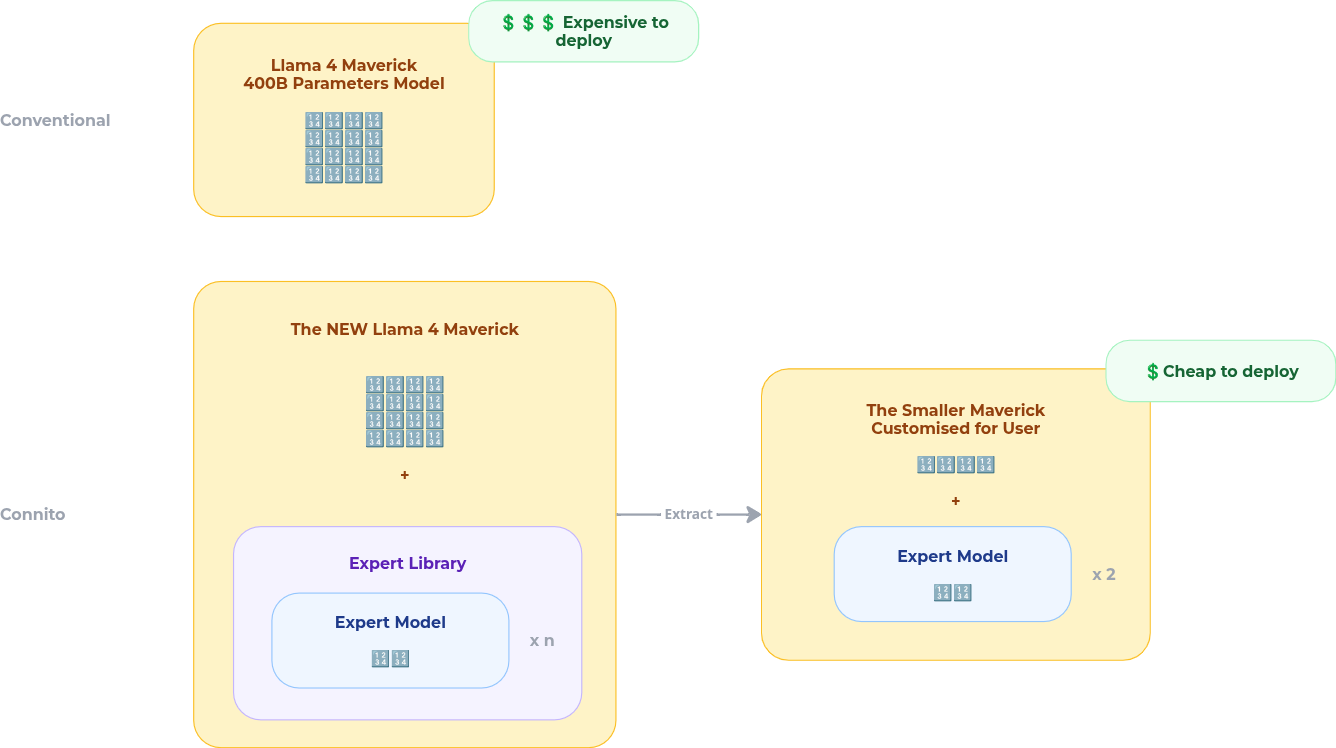
This directly supports:
- VPC deployment: experts run inside the customer's cloud environment
- On-premises: full local hosting with no external data egress
- Air-gapped environments: for regulated industries (healthcare, defense, finance) where data cannot leave the perimeter
Pilot Validation: Math Domain
Following the ESFT methodology (Wang et al., EMNLP 2024), we ran a pilot using DeepSeek-V2-Lite as the base model and a subset of Nemotron-CC-Math as the training data. Rather than fine-tuning the full model, we identified and trained only the math-relevant experts — validating that selective expert training on a decentralized network can produce meaningful domain improvement.
Key results:
- Math domain loss improved steadily across training, confirming that targeted expert updates learn effectively from domain data
- General capability (measured by perplexity on non-math benchmarks) remained stable throughout — no catastrophic forgetting
- The approach matched centralized single-machine training quality, demonstrating that distributing expert training across the Bittensor subnet does not degrade results
Long-Term Ecosystem Vision
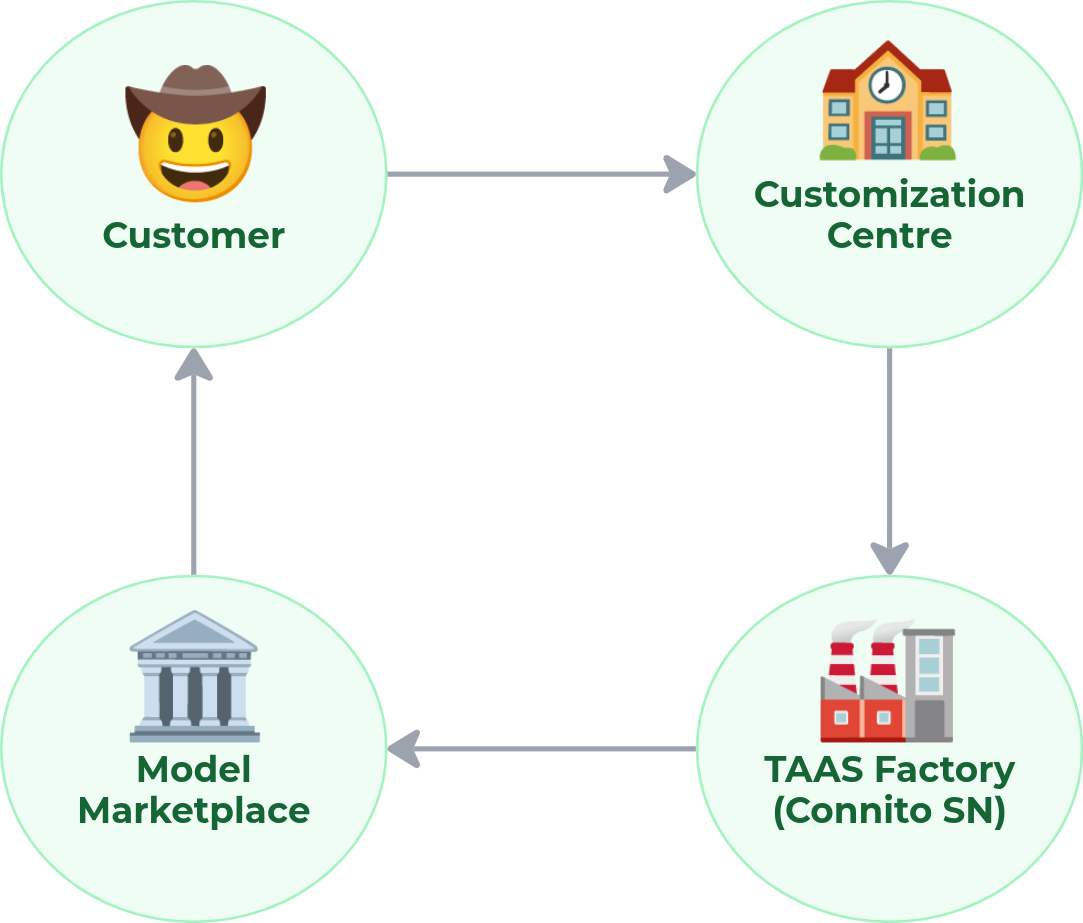
Connito's current form — decentralized expert training as a service — is the first layer of a three-layer ecosystem:
| Layer | What It Does |
|---|---|
| Customization Centre | Transforms customer problems and raw data into structured training tasks |
| TAAS Factory | The Connito MoE subnet — provides distributed training infrastructure for scalable, domain-specific fine-tuning |
| Model Marketplace | Open exchange where trained experts are listed, discoverable, and licensable; contributors earn from model usage |
Together, these layers create a system where models learn from one another, adapt to new contexts, and compound in value with every contribution.
For engineers
Your contribution to the subnet is not just a training run. Every expert you improve becomes a reusable module in the library. Future jobs start from what you built.
For investors
The flywheel: more customers → more experts trained → stronger library → better baselines for new customers → faster time-to-value → more customers.