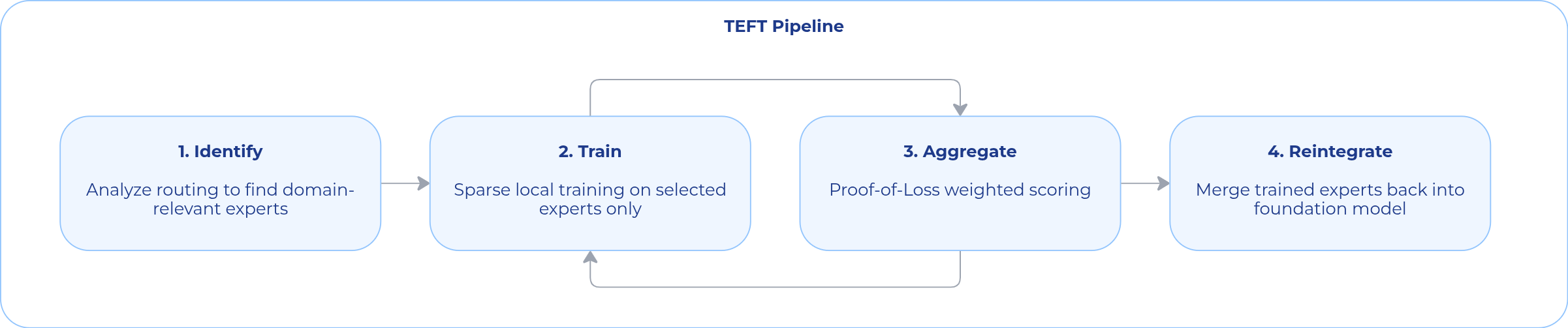
TEFT: Targeted Expert Fine-Tuning
Targeted Expert Fine-Tuning (TEFT) is the optimization framework behind Connito. It enables large Mixture-of-Experts (MoE) models to adapt to new domains without retraining the entire model — and without requiring centralized, high-bandwidth infrastructure.
The core idea is simple:
In an MoE model, only a small subset of experts are responsible for any given domain.
TEFT trains only those experts — and leaves everything else untouched.
This approach is grounded in prior work showing that expert activation patterns are highly domain-specific, and that most experts remain “cold” for a given task (Wang et al., 2024; Li et al., 2025a). Instead of synchronizing the full parameter set, TEFT isolates and updates only the sparse components that matter.
The result: dramatically lower communication cost, preserved general capability, and clean integration back into the base model.
Step 1: Expert Identification
Before training begins, TEFT analyzes routing behavior on the target dataset to determine which experts are consistently activated.
This produces a static index set:
representing the experts most relevant to the domain.
Only these experts are included in the training payload. All other experts remain frozen and are never transmitted across the network.
Because MoE routing distributions are typically highly concentrated (Wang et al., 2024), this subset is small relative to the total number of experts — often a single-digit fraction per layer.
This is the first source of efficiency: bandwidth scales with relevant experts, not model size.
Step 2: Sparse Local Training
Workers download only the selected expert parameters and perform local optimization on their partition of the dataset.
Let:
- denote the current partial model (only selected experts),
- denote a worker’s data shard.
After steps of local training:
Crucially:
- Shared hub parameters remain frozen
- Non-selected experts remain frozen
- Only parameters in are updated
This protects general reasoning ability while allowing domain-specific plasticity.
The worker then submits the new weight rather than full gradients.
Step 3: Proof-of-Loss Aggregation
Validators do not blindly average updates.
Instead, each submitted update is evaluated on a held-out validation set, and only updates with the strongest measured loss reductions are selected for aggregation. In other words, validation performance is used as a ranking signal, not as a direct proportional weight.
For worker , the validator computes the validation loss improvement:
Updates are then ranked by , and only the top- improving updates are retained. The aggregate model update is formed from this selected set, so the resulting weight change depends on the top-performing submissions rather than being proportional to every worker’s observed loss reduction.
If an update does not reduce validation loss, its score is zero and it is excluded from selection.
This mechanism:
- Filters noisy or adversarial updates
- Rewards genuine improvement
- Prevents free-rider behavior
The selected updates are then aggregated using a DiLoCo-style outer optimization step (Douillard et al., 2024), enabling low-frequency synchronization with stable convergence.
Step 4: Reintegration
Once the partial model converges, the trained experts are merged back into the original foundation model by the project owner.
Because only a sparse subset was updated:
- General knowledge remains intact
- Unrelated experts are unaffected
- Domain specialization is cleanly isolated
Empirical evidence from partial-model experiments shows that updating only domain-relevant experts can achieve strong in-domain convergence while maintaining stable out-of-domain perplexity (see literature review).
Why TEFT Works
TEFT leverages three empirical properties of modern MoE models:
- Expert sparsity — Only a small subset of experts are active per domain.
- Expert modularity — Experts can be updated independently.
- Sparse utilization — Many experts contribute minimally for any given task.
These properties are repeatedly observed across MoE literature, including ESFT (Wang et al., 2024), DES-MoE (Li et al., 2025a), and pruning analyses (Chen et al., 2022).
Instead of fighting MoE sparsity with dense synchronization, TEFT aligns with it.
The Result
TEFT transforms MoE adaptation from a monolithic training job into a sparse, modular, verifiable optimization process.
It achieves:
- Orders-of-magnitude lower communication overhead
- Protection against catastrophic forgetting
- Incentive-aligned aggregation
- Compatibility with decentralized infrastructure
Rather than asking every node to train the entire model, TEFT asks:
Which experts matter for this domain — and who can improve them?
That shift makes large-scale collaborative adaptation feasible.