What Is a Mixture-of-Experts Model?
A Mixture-of-Experts (MoE) model replaces the dense feed-forward block in a transformer with a collection of specialized subnetworks — called experts — coordinated by a routing mechanism.
Instead of activating every parameter for every token, an MoE model activates only a small subset of experts per token. This idea was first introduced at scale in Shazeer et al., 2017 and later extended in Switch Transformers (Fedus et al., 2022), which demonstrated that sparse models could scale to trillions of parameters while keeping inference cost manageable.
Today, sparse MoE architectures underpin many frontier models, which includes DeepSeek-V3, Qwen3, Mixtral 8x7B and Meta’s Llama 4.
How MoE Routing Works
A traditional transformer layer contains a dense feed-forward network (FFN). In that design, every parameter in the FFN is activated for every token. No matter what the input is — code, math, dialogue, or poetry — the entire block participates in the computation.
A Mixture-of-Experts (MoE) layer changes this fundamentally.
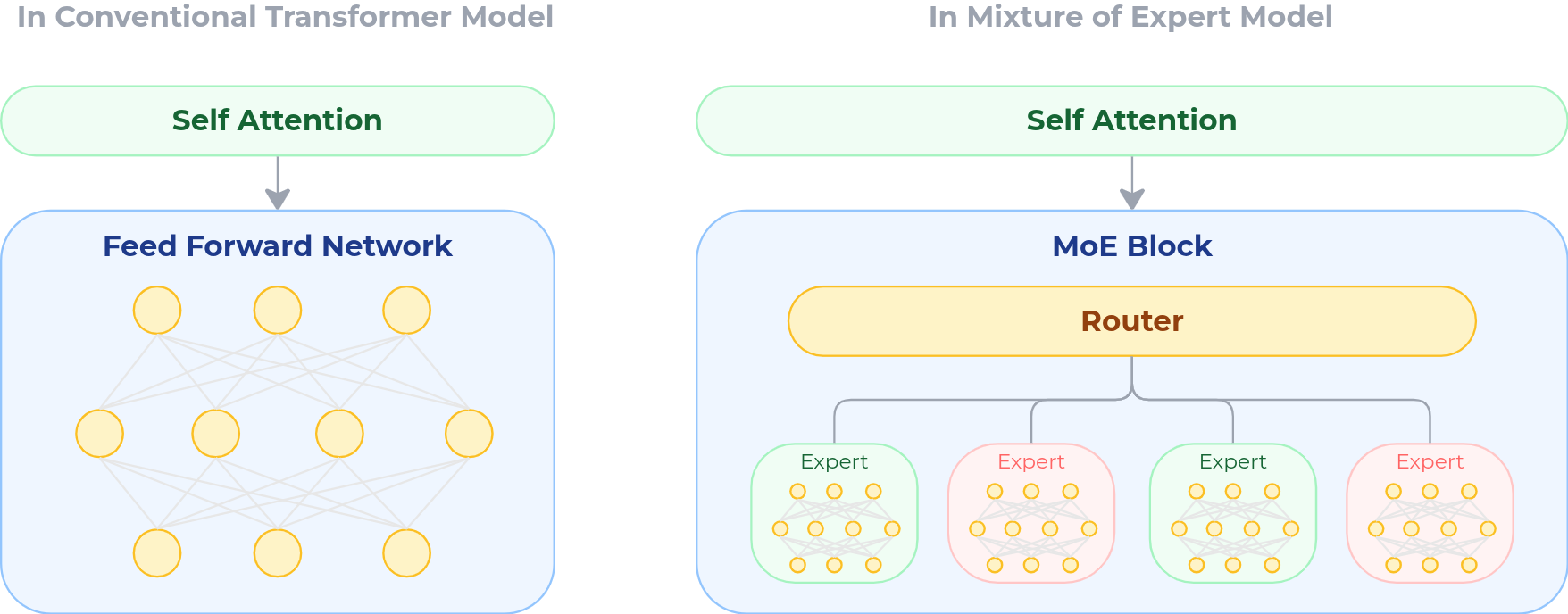
Instead of one large feed-forward network, the layer contains many smaller subnetworks called experts. Each expert can specialize in different patterns or domains. Some may become stronger at mathematical reasoning, others at syntax, others at multilingual text. Alongside these experts sits a router — a lightweight gating network whose job is to decide which experts should process each token.
Formally, the model can be described as containing:
- Shared parameters that process all tokens (attention layers, normalization layers, etc.),
- A router that computes expert selection probabilities,
- A collection of expert parameters, indexed by layer and expert number.
For an input token representation at layer , the router computes a score for each expert and selects only the top- experts. The remaining experts are ignored for that token.
The layer output is computed as a weighted sum of the selected experts:
Here, is the input to layer , is the number of selected experts, is the routing weight assigned to expert , and is the output of expert on input . The final output is the weighted combination of these expert outputs.
In practice, although there may be dozens or even hundreds of experts in a layer, only a small number — typically 3% — are active for any given token.
How MoE Changes Scaling
The key difference in an MoE model is that model capacity and per-token computation are no longer tightly coupled.
In a dense transformer, increasing parameter count also increases the amount of computation required for every token. In an MoE model, those two quantities can scale separately:
- the total parameter count grows with the number of experts available in the model;
- the active compute per token depends only on the small subset of experts selected by the router.
As a result, an MoE model can increase total capacity substantially without increasing inference cost in proportion. This is the central reason sparse architectures are attractive at frontier scale: they allow the model to store far more specialized behavior than a dense model with similar per-token FLOPs.
Recent work such as Unified Scaling Laws for Routed Language Models formalizes this observation. It shows that routed models scale along two distinct axes: the total number of parameters available in the model ~, and the amount of computation actually used per token ~. MoE is therefore not just a way of making models larger, but a way of making scaling more compute-efficient.
Why MoE Fits Decentralized Training
The same property that makes MoE efficient at scale — activating only a small subset of parameters per token — also makes it well suited to decentralized training.
Because computation and gradient flow are sparse, MoE models are not updated as one monolithic parameter tensor. Instead, training is concentrated in the small subset of experts selected by the router. This creates a natural degree of modularity: different expert blocks can be specialized, trained, and synchronized more independently than in a dense model.
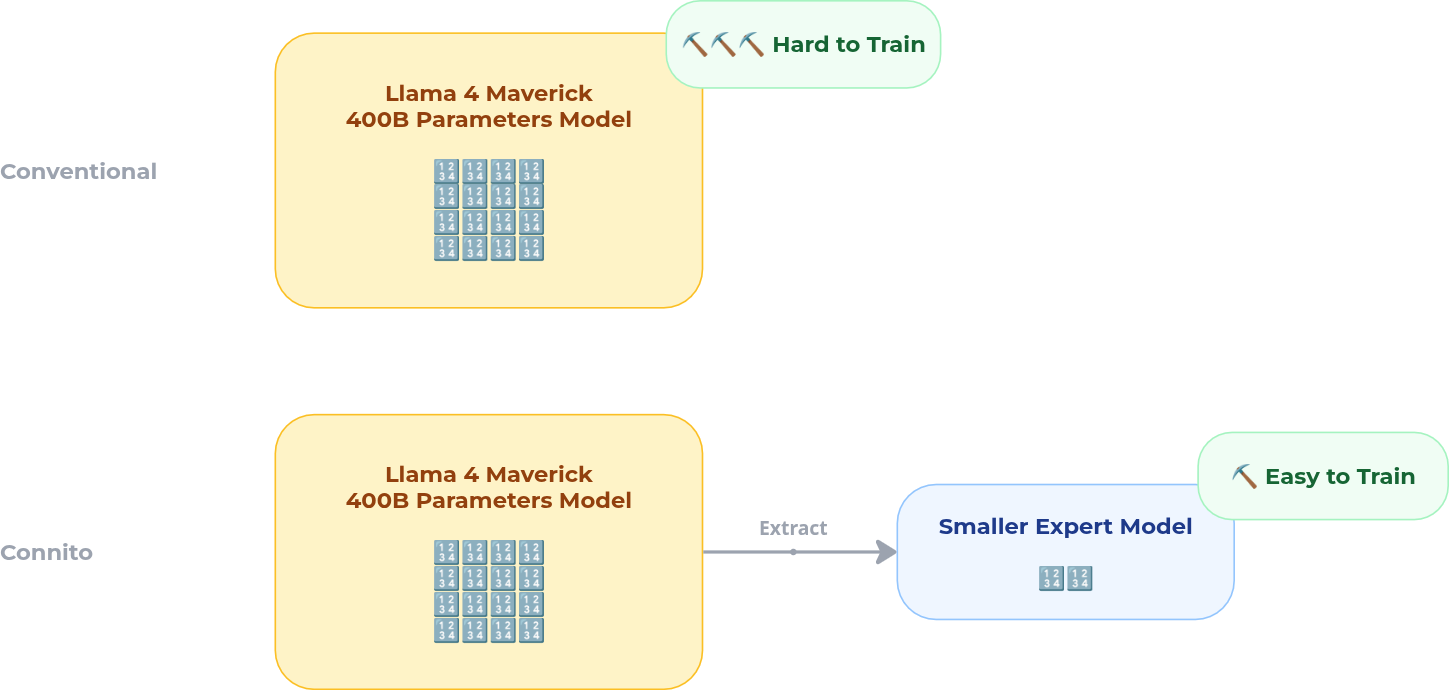
This is the core reason Connito uses MoE. Rather than fine-tuning the full model for every domain, the system can focus training on the expert subsets that are actually active for that domain, making adaptation more tractable, more communication-efficient, and more naturally parallelizable.
1. Modular Expert Boundaries
Experts are self-contained subnetworks. Since only a subset of them are active for any given token, updates are naturally localized. Research such as Expert-Specialized Fine-Tuning (Wang et al., 2024) shows that routing is highly concentrated within domains, meaning that only a small set of experts tends to dominate for a given type of data.
This allows distributed participants to work on different expert subsets with limited interference.
2. Sparse Communication
In dense training, synchronization typically requires communicating updates across the full model. In MoE training, only the active experts need to be updated or exchanged for a given workload.
That sparsity substantially reduces communication overhead. Combined with low-communication training methods such as DiLoCo (Douillard et al., 2024), this makes decentralized coordination much more practical than in dense data-parallel systems.
3. Domain Specialization
A defining empirical property of trained MoE models is that experts do not remain generic. They specialize. Tokens from domains such as code, mathematics, or legal text tend to activate overlapping subsets of experts, and those routing patterns are often stable across data distributions. Results from Wang et al., 2024 and interpretability work such as Hu et al., 2026 support this view.
For Connito, this means fine-tuning can be localized: adapting to a new domain often requires updating only the experts that already carry that domain’s behavior.
4. Composability
MoE models are also easier to compose than dense models. Branch-based approaches such as Branch-Train-MiX (Sukhbaatar et al., 2024) show that experts trained independently can later be merged into a unified routed model.
This makes decentralized coordination feasible at the system level: different participants can train or improve experts in isolation, and those experts can later be integrated without retraining the full foundation model.